LM
Language Model 이란 ?
단어의 sequence(즉, 문장)에 대해 얼마나 자연스러운 문장인지를 확률을 이용해 예측하는 model이다.
즉, 주어진 단어의 sequence에 대해 다음에 나타날 단어가 어떤 것인지를 예측하는 작업이 Language modeling이다.

확률을 이용하여, 과거의 단어들을 기반으로 앞으로 나타날 단어 중 확률이 높은 단어를 다음에 나타날 단어라고 예측하는 것 !
LM은 기계번역, 음성인식, 자동완성 등등에 활용할 수 있다.
n-gram Language model
LM 중에서도 n-gram을 바탕으로 만들어진 model이다.

neural network 이전에 사용되었던 LM 으로, 예측에 사용할 앞 단어들의 개수를 정하여 modeling하는 방법이다.

특정 n-1개의 단어를 이용하여 이후 단어를 계산하는 것이다.
그러나 N-gram LM은, sparsity problem이 있다.
(n이 커질수록 분모와 분자에서 동시에 나타날 수 있거나, 분자 또는 분모에서 아무것도 나타나지 않는 문제 )
이를 해결하기 위해서는 n의 숫자를 낮춰주거나 (back-off), 전체 단어의 개수만큼 count해주고 0이 나오면 작은 값의 delta를 더해주(smoothing)기도 한다.
또한 n이 커지거나 corpus가 증가하면 model 크기가 증가한다는 storage problem도 있다.
Neural Network LM
n-gram의 문제점, 특히 curse of dimensionality를 해결하기 위해 제안된 model로,
LM이면서 동시에 단어의 distributed representation을 학습하도록 한다.

고정된 window size(다음 단어를 예측하기 위한 과거의 고정된 크기)의 index가
embedding layer를 통과하여 각 단어의 embedding vector를 뽑아낸 후, (이를 통해 sparsity probelm 해결)
각 단어의 sequence가 맞게끔 concat한 후,
hidden layer와 softmax layer를 통과하여, 각 단어의 확률 분포를 구하는 것이다.
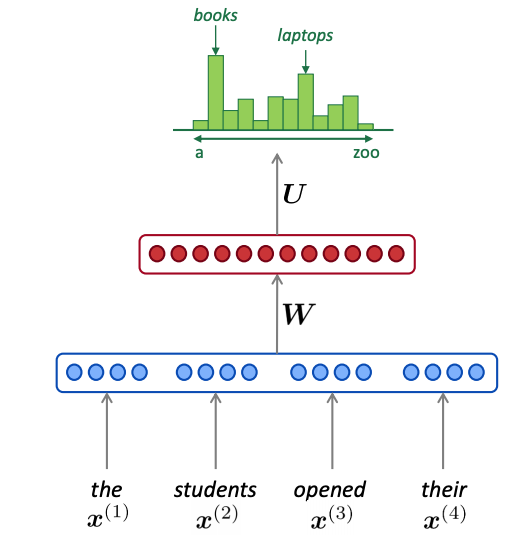
그러나 window size가 작다는 문제가 있는데, window가 커질수록 위 그림에서의 W도 커지기 때문이다.
또한 각 x1, x2는 완전히 다른 가중치 W가 곱해지기 때문에 단어간의 symetry하다는 문제가 있다.
RNN Language Model
Neural Network LM을 보완하기 위해 RNN LM이 제안되었다.

핵심적인 아이디어는 “동일한 가중치 W를 반복적으로 사용한다”는 것이다.
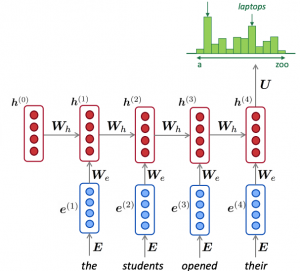
input 길이에 제한이 없고, 길이가 긴 timestamp에 대해서 처리 가능하며(이론상),
input에 따라 model의 크기가 증가하거나 하지 않으며 매 timestamp마다 동일한 W를 적용함으로서 symmetry하다는 장점이 있다.
그러나 recurrent 계산이 느리고, 실제로는 길이가 긴 timestamp에 대해 처리 불가능한 단점이 있다.

evaluatung language model

LM model의 평가를 위해서는, 출현할 단어의 확률의 역수인 perplexity를 사용한다.
perplexity 값이 작을 수록 좋은 LMd이당.