Machine-Translation (MT)
MT는 1950년대 rule-based system 을 기반으로 시작되었으며,
현재는 seq-to-seq을 기반으로 하는 Neural Machine Translation(NMT)가 주로 연구되고 있다.
기계 번역에 성능을 평가하기 위해 쓰이는 BLEU,

BLEU는 n-gram을 바탕으로 순서쌍들이 얼마나 겹치는지를 측정하는 것이다(precision)
그러나 정성적으로는 더 문장임에도 score가 낮게 나올 수 있어, 불완전한 measure 이다.
Statistical Machine-Translation (SMT)
주어진 parallel data로부터 확률 모델을 구축하는 것이 core idea이다.

프랑스어 문장을 영어문장으로 바꾸는 문제를 예로 들면,
프랑스어 문장 f가 주어졌을때 최적의 영어 문장(best e)이 나올 확률을 최대화하는 E를 찾는 것이다.
이를 위해서는 대량의 parallel data(매칭되는 영어 문장과 프랑스 문장 pair)가 필요하고,
의미가 일치하는 단어 또는 구를 찾아서 짝을 만들어주고 (Alignment), 이러한 Alignment를 학습한다.

이 과정이 쉽지 않은게, One-to-One이 아니라 One-to-many 또는 Many-to-one으로 alignment되는 경우가 엄청 많기 때문이다.
이후 어떤 문장이 f의 최적의 문장 (best e)인지 찾기 위해서, 모든 확률을 다 계산하는 건 너무 cost하기 때문에
Beam Search 등 heuristic한 search algorithm을 사용해 계산량을 줄인다. 이 과정을 Decoding이라고 한다.
SMT는 매우 복잡한 구조와, 여러개의 subcomponents로 분리되어있으며 많은 feature engineering이 필요하다는 단점이 있다.
Neural Machine-Translation (NMT)
Neural Machine-Translation 이란, 하나의 Neural Net model을 end-to-end로 학습시켜서 기계 번역을 시도하는 것이다.
SMT의 한계는 NMT를 통해 많이 해결할 수 있으며, 현재 많이 사용되고 있다.
NMT는 기본적으로 Encoder와 Decoder, 두개의 RNN을 이어붙인 Sequence-to-Sequence model을 기본 형태로 가진다.
SMT에 비해 성능이 좋으며 단일 모델을 사용하고, 상대적으로 engineering task가 적지만,
해석이 쉽지 않아 debugging이 어렵고, 특정 규칙이나 가이드라인을 번역에 쉽게 적용하기 어렵다는 단점도 있다.
Sequence-to-Sequence
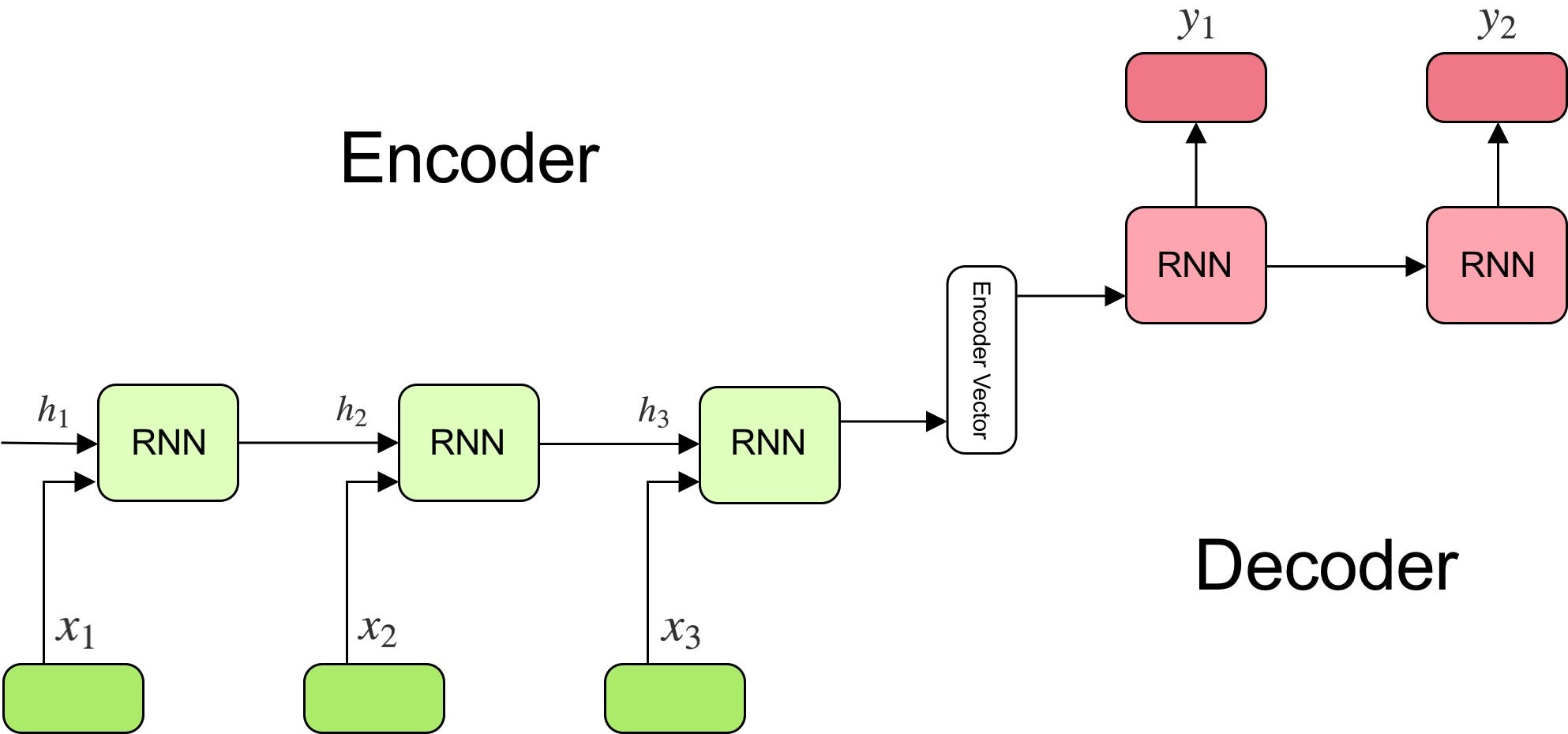
Seq2Seq은 Encoder와 Decoder, 두개의 RNN을 이어붙인 model이다.
Encoder에서는, RNN을 거쳐 source sentene의 context정보를 요약한다.
이런 context정보는 last hidden state에 모이게 되고, 이를 Decoder로 전달하여 initial hidden state로 사용한다.
Decoder에서는 전달받은 source sentence의 context 요약 정보를 기반으로 target sentence를 생성한다.
(이런 점에서, decoder RNN은 conditional language model의 한 종류로 볼 수 있다. )
decoder에서 target sentence를 생성하는 과정에서 heuristic searching algorithm 이 사용된다.
(e.g. Exhaustive Search Decoding, Greedy Search Decoding, Beam Search Decoding, … )
Seq2Seq은 end-to-end로 backpropagation이 일어난다.
Seq2Seq을 기반으로 summarization, dialogue, parsing 등등 다양한 NLP task를 해결할 수 있다.
Seq2Seq에서의 hyperparameter 중, decoder에서 실제 정답 data를 사용할 비율을 설정하는 teacher-forcing이 있다.
초기에 잘못 생성한 단어로 인해 계속 잘못된 문장이 학습되는 경우를 막기 위함이며,
teacher-forcing를 높게 설정할수록 빠른 학습이 가능하지만 overfit 문제도 발생한다.
inference 단계에서는 teacher-forcing=0으로 설정하여, 모델이 생성한 단어만으로 다음 단어를 예측한다.
Attention
기존 vanilla RNN을 기반으로 하는 Seq2Seq model은 source sentence 및 encoder에서 얻은 context를 모두 decoder에 전달했는데,
information bottleneck을 일으킬 수 있다.. 그래서 attention 기법을 이용하여 이를 보완하였는데,
핵심 idea는 decoder의 매 step마다 source sentence의 특정 부분에 집중하기 위해 encoder와 직접적인 연결을 사용하는 것이다 (attention vector)
유투브 영상(https://www.youtube.com/watch?v=c8y9ZAb9aks&list=PLetSlH8YjIfVdobI2IkAQnNTb1Bt5Ji9U&index=7)에서 정리를 되게 잘 해두셨길래 캡쳐해서 가져왔답




Attention을 사용하면 NMT의 성능이 매우 향상되고, bottleneck problem도 해결할 수 있으며
멀리 떨어진 hidden state 끼리의 지름길을 제공함으로서 vanishing gradient problem을 완화하는데 도움이 되고
alignment를 별도로 구성하지 않아도 얻을 수 있다(network가 alignment를 스스로 학습)
Attention 기법 자체는 query와 value벡터가 주어졌을때 query에 기반해 value의 weighted sum을 구하는 기법으로,
general한 DL에서 활용이 가능하다 !