Chap 11 에서는 , ConvNet이 nlp에서 어떻게 쓰이는지에 대한 내용이다.
1. CNN
전체에 대해 계산한 후 해당 token을 계산하는 RNN은,
아무래도 직전 hidden state의 영향을 가장 많이, 이전 state로 갈수록 영향이 희미해진다. (vanishing gradient)
이를 보완하기 위해, encoder 단에서 attention을 적용하는 등 다양한 시도가 있었다.
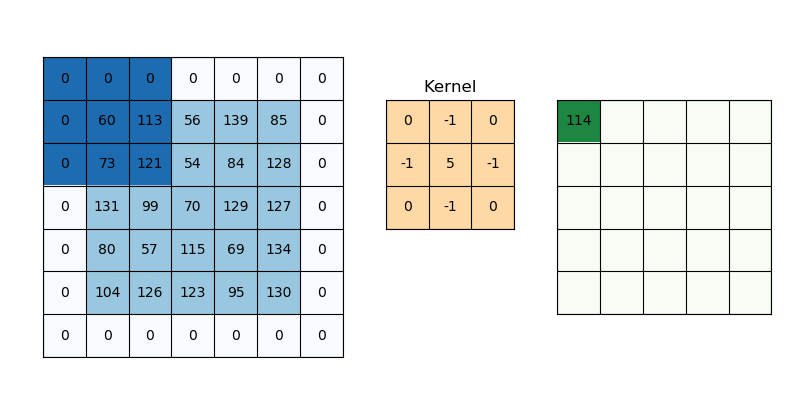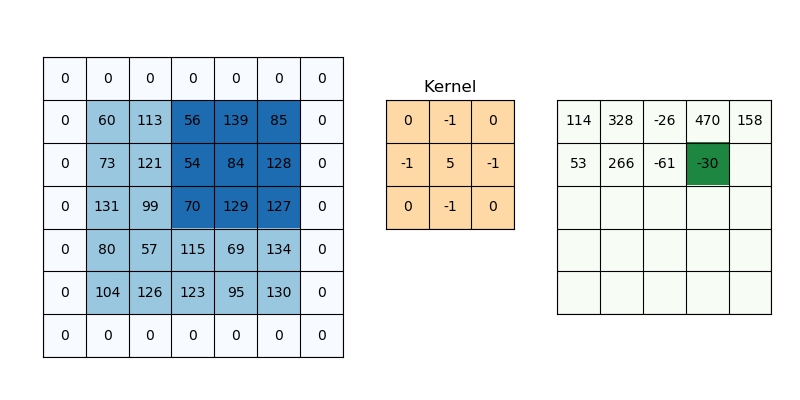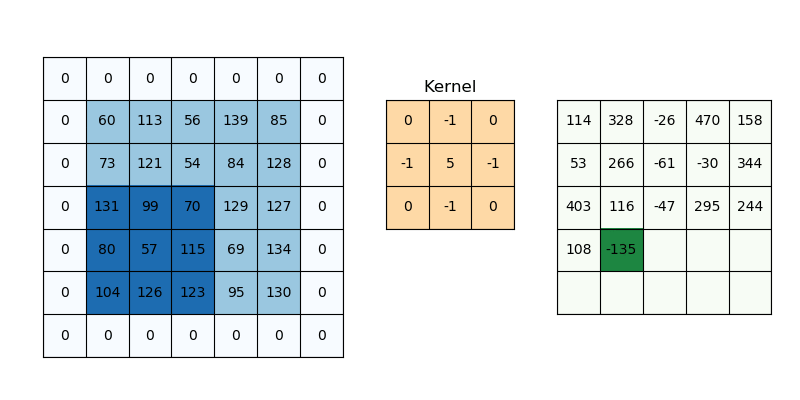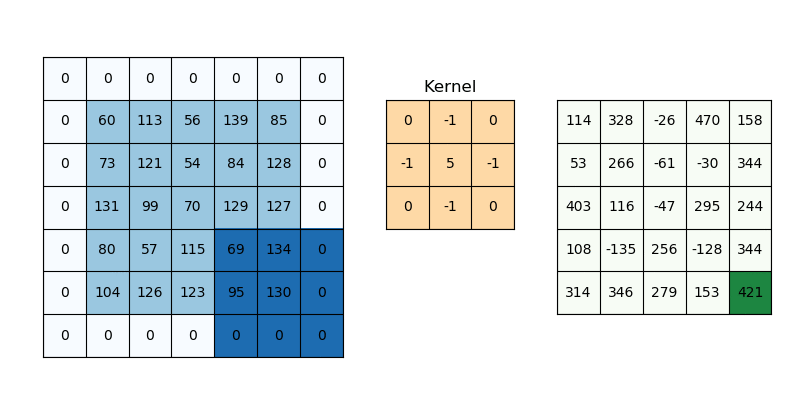
반면 CNN은, 특정 길이의 sub-sequence로 분할 후 feature를 추출할 수 있다.
그러나, 임의로 분할해버리면 문법적으로 맞는지 확인할 수 없어, 주로 vision 분야에서 많이 쓰였다.
2. 1dCNN for Text

text에서의 CNN은, 하나의 token에 대해 embedding된 vector를 가지고 한방향으로 진행하기 때문에 (좌우 상하가 아니라 좌우로만 이동)
일반적인 2DCNN이 아닌 1DCNN이 쓰인다.
padding, pooling 모두 나머지 과정이야 똑같은데, nlp에서는 average pooling을 많이 쓰인다.
3. CNN for Sentence classification
1x1 Convolution에서는 kernel size를 1로 두어, 적은 parameter를 사용하여 channel을 축소할 수 있다.
이를 통해 fully connected layer에서 바로 input으로 쓸 수 있다.
또한 batch normalization 을 통해, parameter initialization에 덜 민감해지고 learning rate에 대한 tuning이 더 쉬워진다
이를 활용해 sentence classification을 진행하는 pilot study도 많다.