Chap 12 에서는 ,
1. Linguistic knowledge
언어학에는, 소리 체계를 연구하는 Phonology(음운론),
단어의 어형 변화를 연구하는 Morphology(형태론)이 있다.
또한 언어마다 음절문자인지, 소리문자인지, 의미문자인지 등등이 다르다..
대부분 model을 character 기반으로 만드는데, 이를 통해 unknown word를 파악할 수 있고,
connected language를 분석할 수 이쓰며, character n-gram으로 의미를 투출할 수 있다
예를 들면, unhappyness를 5-gram으로 표현하면 unhap, nhapp, happy, …, 이렇게 !
2. Byte-Pair Encoding (BPE)

일반적으로 embedding된 단어의 matrix에서, sequence 별로 voab 내의 word vector를 가져온다.
그러나 vocab의 크기가 제한적이므로, vocab에 없으면 OOV problem이 발생한다.

BPE는 원래 정보 압축을 위해 제안된 알고리즘으로 최근 자연어 처리 모델에 널리 쓰이고 있는 토큰화 기법이다.

이렇게 자주 나타나는 단어를 치환하는 것 !! BPE는 BERT에서도 쓰였다.
3. Sub-word Models

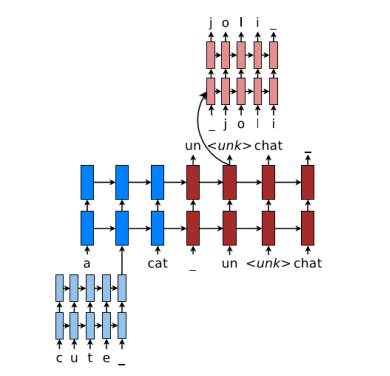
character-level NMT model인 Sub-word Model(Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation)은,
character embedding에 Bi-LSTM을 이용했으며, 마지막 hidden state를 concat해서 embedded word vector로 사용한다.
embedded vector들을 윗단계 LSTM에서 최종 task를 진행한다.
이후 이를 활용한 논문들이 많이 발표되었다.