Chap 13 에서는, Contextual Word Representation and Pretraining
즉 기존 word representation과 Contextual representation 그리고 이를 바탕으로 하는 pre-training model을 설명한다.
1. Reflections on word representation
2011년 전까지는, 그 당시의 SOTA(State-of-the-art) model은 주로 DL이 아니라 rule-based 또는 ML이었으며
pre-training + supervised NN 을 활용한 경우 성능이 조금 더 나아졌었다.
2014년 이후에도 일반적으로는 word vector를 random initialization시킨 후, task에 맞게 학습하였다.
다만 Glove 등으로 pre-train시키면 아무래도 task에 쓰이는 labeled data보다 훨씬 더 많은 unlabeled data에 의해 학습되다 보니, 성능 향상에 도움이 되었다.
그 중에서도, pre-train시 잘 등장하지 않는 (5회 이하) 단어들을 unknown, 즉 <UNK>로 처리하고 test할때 out-of-vocabulary를
이렇게 되면 <UNK>로 매칭된 단어가 중요한 뜻을 지닐 수 있는데, 이를 놓칠 수 있다,,
이를 해결하기 위해, 아래와 같은 해결책이 제시되었다.
-
Char-level embedding model 사용
-
pre-train된 word vector를 사용 -> 대부분 사용하는 방법
-
OOV 단어의 경우 random initialization를 부여하고, 단어를 vocabulary에 추가
이처럼 단어 하나 당 하나의 representation(vector)로 나타내면, context마다 다른 의미를 가진 단어가 모두 같은 represenation을 갖게 되어 문맥을 고려할 수 없게 된다.
이를 해결하기 위해 LSTM Language Model(문장을 입력하면, 문장 뒤의 단어를 예측함)을 사용하는데,
LM의 input은 주로 pre-training 또는 random initialization된 word vecdtor인데,
학습 과정에서 context-specific word representation을 나타내게 된다.
2. Pre-ELMO and ELMO
context-specific word representation를 사용한 예시가 ELMO이다.

ELMO 이전에 나왔던 pre-ELMO를 잠깐 살펴보면, Neural Language Model을 large unlabeled corpus에 응용한 것인데
RNN 으로 context에 담긴 뜻을 학습하고 싶지만, task 학습에 이용되는 data는 small task-labeled data이다.
그래서 large unlabeled corpus로 먼저 학습을 시키는 semi-supervised approach를 사용하는 것ㄷ이다.

pre-ELMO는 NER benchmark dataset에서 좋은 성능을 이루었다.
ELMO(Embeddings from Language Models)는 NER위주였던 pre-ELMO를 좀 더 일반화해서 나타낸 모델로,
모든 문장을 이용해 contextualized word vector를 학습하는 것이다. (!=기존 word embedding이 window를 이용해 주위 context만 고려)
이때, word embedding은 Char CNN만을 이용하고,
지난 LSTM의 결과물과 이번 LSTM의 input을 합쳐서 이번 input으로 사용하는 residual connection을 사용했으며,
CNN과 LSTM 사이에 projection layer(CNN에서 LSTM으로 넘어가는 parameter 수를 줄임)를 사용했다.
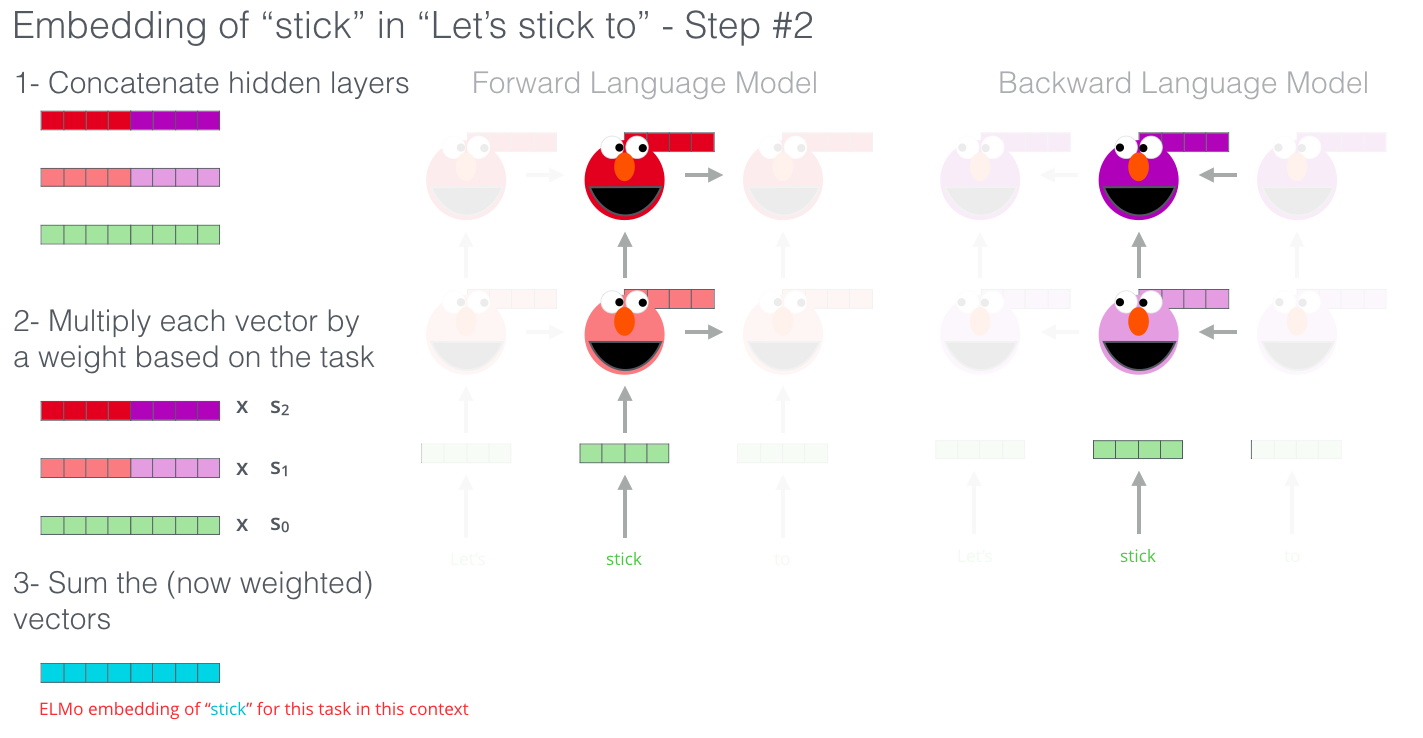
ELMO는 bidirectional Language Model로서 forward LM은 문장 sequence에 따라 다음 단어를 예측하도록 학습되며 backward LM은 뒤에 있는 단어를 통해 앞 단어를 예측하도록 학습된다.
forward LM과 backward LM의 결과를 layer별로 concat한 후,
concat된 layer별 출력에 정규화된 가중치를 곱해주며(linear combination) 학습을 통해 최적화하여, 최종적으로는 모든 layer의 벡터를 더해 하나의 embedding vector라는 word vector를 만들게 된다.
이때 LM의 state 즉 weight는 freeze되고, linear combination의 값은 학습된다.
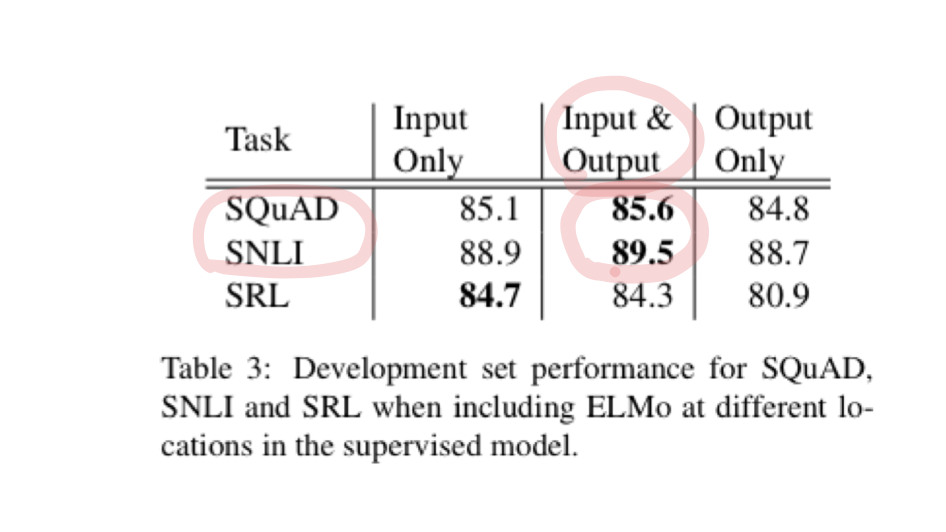
ELMO는 NER 뿐 아니라 다양한 task에서도 SOTA를 기록하였다.
3. ULMfit and onward
이후 등장한 ULMfit(Universal Language Model Fine-tuning for Text Classification)은
NLP에서 본격적으로 transfer learning을 도입하였고, 1개의 GPU로 학습이 가능할 정도의 small dataset으로 pre-training 했다.
transfer learning이란, 큰 dataset(general objective function을 가지는)에 대해 먼저 학습을 시키고,
이후 small dataset(specific object function을 가지는 task)에 대해 fine-tuning을 하는 것이다.
다만 ELMo와 달리, feeze 시키지 않고 전체적으로 fine-tuning을 하는 것이다.
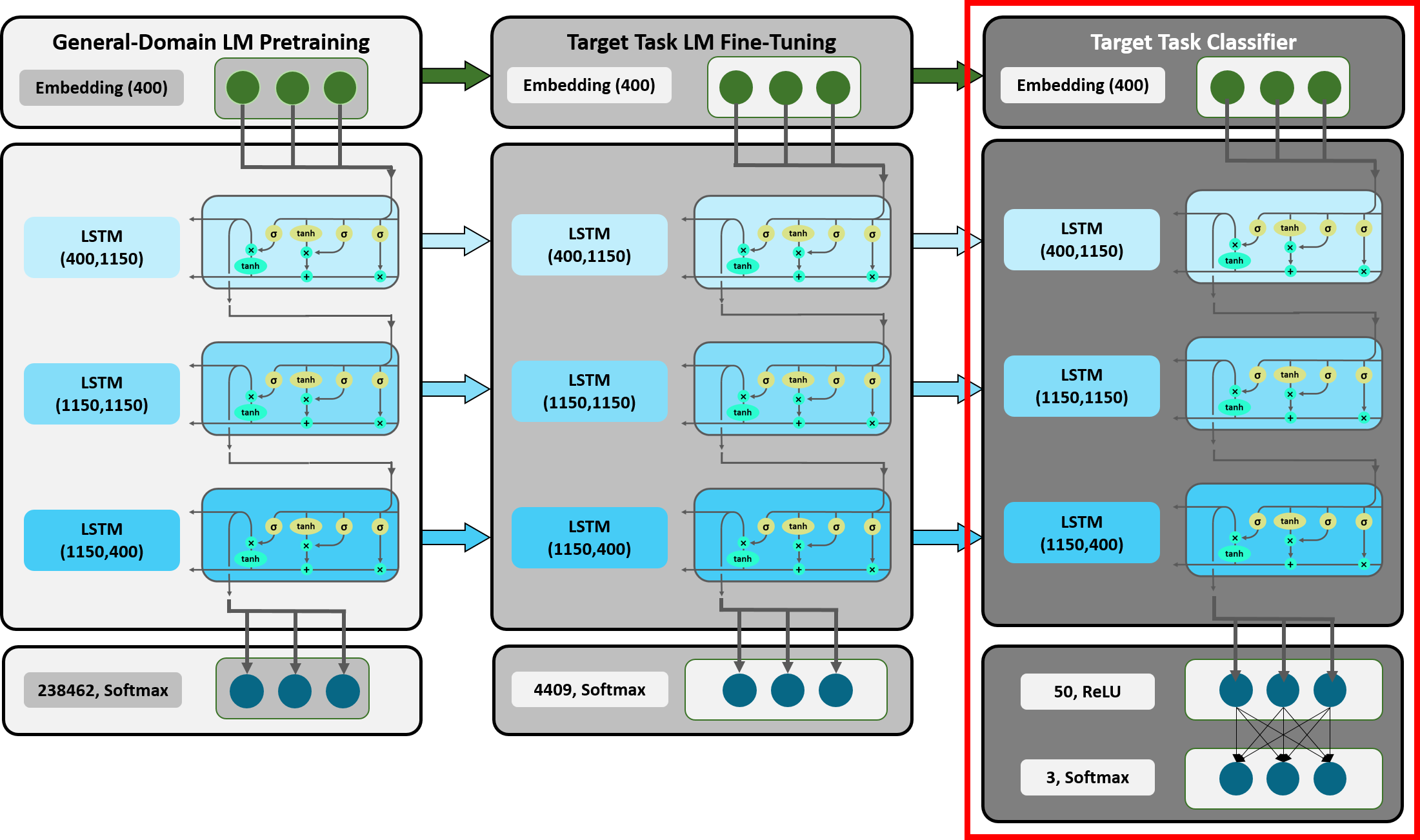
-
3-layer Bi-LSTM Language Model로 pre-training
-
target task에 맞춰 LM fine-tuning
- 이때, layer별로 다른 learning rate를 적용하거나, slanted triangular learning rate를 적용한다.
- target task의 classifier를 fine-tuning
- 이떄, 마지막 Layer부터 천천히 gradient를 흘려보내는 gradual unfreezing 기법을 적용한다.
위 결과에서, pre-training이 얼마나 강력한지 알 수 있다.
이후, model parameter를 ㄴㄹ려 LM pre-training 하는 model들이 등장했다.
이에 따라 필요한 resource가 기하급수적으로 증가하였다,,,
4. Transformer architectures
기존에 사용했던 LSTM LM 등 RNN 계열 알고리즘은 Sequential 하기 때문에 parallelize가 불가능했다.
또한 긴 입력에 대한 Long-term Dependency 문제가 항상 존재했었다.
LSTM, GRU로 해당 문제를 어느정도 해결할 수 있었지만 완전히는 불가능했으며 Attention(특정 time step으로 이동할 수 있게 도와주어 sequential한 특징에서 자유로움)이 필요했다.
그렇다면 RNN 말고 그냥 Attention만 써보면 어떨까 ? 하는게 motivation 이었다.

우선은 Attention으로만 Seq2Seq model을 구현했고, 자세한 내용은 예전에 정리해둔 글과 같아서 생략한다.
다만 Encoder에 대해 되게 잘 정리해둔 글이 있어 일부를 가져왔다.
Transformer는 기계 번역을 위해 존재하는 input과 output이 encoder와 decoder로 구분되어 진행되는 seq2seq 모델입니다. 이 때, decoder의 어떤 step과 encoder의 전체 step 중 가장 연관성 있는 한 step을 찾아가면서 보다 효과적인 seq2seq 과정을 거치게 됩니다.
Attention이 모든 state를 참조할 수 있다는 의미는 decoder에서 output으로 나오는 매 step마다, encoder의 전체 step을 참고하기 때문입니다. 이 때, decoder가 encoder를 참고하는 과정에 있어 decoder의 단어와 step에 따라 attention value가 달라지게 됩니다.
.
.
self-attention이란 자기 자신의 query로 attention value를 구하는 것으로, 그림과 같이 특정 단어가 자신의 문장에서 다른 단어와의 attention value를 구함으로써 dependency와 같은 value의 높고 낮음을 구할 수 있게 됩니다.
.
.
Multi-Head Attention이란 새로운 개념이라기 보다는 앞서 설명한 attention 매커니즘이 여러번 적용된 개념입니다. Multi-Head가 의미하는 것은 다양한 관점에서 바라볼 때, 보다 풍부한 정보를 얻을 수 있다는 것에 착안하여, attention을 다수로 진행함으로써 보다 많은 정보를 가져와 projection하여 다음 layer에 전달하는 과정을 말합니다.
# https://velog.io/@tobigs-text1314/CS224n-Lecture-13-Contextual-Word-Embeddings

그림도 잘 그리셔서 가져왔다,,, ㅎ
Decoder에서는, target sequence에 대해 multi-head attention을 적용하는데
masking을 통해 query가 이전 timestamp의 key 단어만 보게끔 하였다.
5. BERT
BERT는 Transformer의 encoder부분을 차용하여 만든 Bi-directional Language Model이다.
forward LM과 backward LM을 모두 적용함에도 불구하고 단어를 예측함에 있어 전체 단어를 모두 활용할 수는 없다는 것을 보완하고자 하였다.
사실 기존의 bi-direction은 forward LM, backward LM을 같이 활용한다고 해도 결국은 각 모델은 단방향 예측만 가능한데,
Bi-directional 예측이 한번에 가능하다면 가운데 들어갈 어떤 단어를 예측함에 있어 보다 많은 정보를 기반하여 가능하게 된다.
구체적인 구조 및 pre-train 과정도 예전에 설명하였으니 생략하도록 하겠다.
BERT는 MLM(Masked Language Model)을 사용하여 Bi-directional이 가능하도록 했는데,
문장에 존재하는 단어 중 일부를 masked 처리한 뒤에, maksed 처리된 단어를 나머지 모든 단어로 예측함으로서 masked된 단어를 제외한 모든 단어를 활용할 수 있게 되면서 forward과 backward의 모든 문맥을 한번에 고려할 수 있게 된다.
BERT는 2가지 objective function을 갖는데, MLM과 NSP 이다.
(cost function, loss function, objective function에 대해)
NSP(Next Sentence Prediction)이란, sentence 간의 relationship을 학습하기 위해 두 문장이 이어지는지에 대한 정보를 학습하는 것이다.
BERT가 NSP 도 objective function으로 넣은 이유는, BERT가 2개의 단어를 사용해야 하는 objective를 잘 수행하기 위해서이다.