- Transformer & self attention
self attention으로 해결하고 싶은 문제는
seq2seq에서의 다양한 길이의 input data를 어떤 learning mechanism에 넣어서 고정 크기의 vector or matrix로 표현하는 것이다
이후 NMT QA summarization 등 task에서 이렇게 바꾼 vector or matrix를 쓴다
그럼 이 learning mechanism은 어떤 걸까 ? 일반적으로는 RNN 계열 model이 쓰이지만, (LSTM,GRU,..)
RNN 계열 model들은 parallelization이 불가하고 long term dependency를 잘 반영하지 못한다는 문제가 있다
CNN 계열 model을 쓰더라도, long term dependency문제 해결을 위해서는 다수의 layer가 필요하다는 단점이 있다
self attention은 병렬화가 가능하며 각 token이 최단 거리로 연결되어 있어 long term dependency문제도 해결할 수 있다
각 token의 embedding vector에 대해, 다른 token의 embedding vector와 dor production, softmax를 통해 attention score를 구하고, 이를 기반으로 모든 token의 weighted sum을 통해 각 token의 representation vector를 얻을 수 있다
이처럼 self attention은 RNN,CNN을 대체하는 하나의 learning mechanism으로서 다양한 모델에서 쓰일 수 있게 된다
또한 각 token들을 sequence 내 모든 token과의 연관성을 기반으로 re-express하는 과정으로 해석할 수 있다
구체적인 self attention flow를 살펴보면,
- input의 각 token을 linear transform하여 query,key,value을 생성
- query와 key pair의 dot product를 계산한다 (QK^T)
- scaling을 통해 scaled dot product attention을 만듦 (각 값의 분산을 줄여주어 gradient 전파가 잘 됨 & 다양한 값 적용가능)
- 3의 값에 softmax function 적용
- 4를 weight로, value vector들의 weighted sum을 산출
transformer에서는 여러번 self attention하여(multi head attention) 한 문장 내에 담긴 다양한 정보를 캐치하고자 하였다 즉 서로 다른 scaled dot product attention을 여러번 적용하여 concatenation하고자 하였다
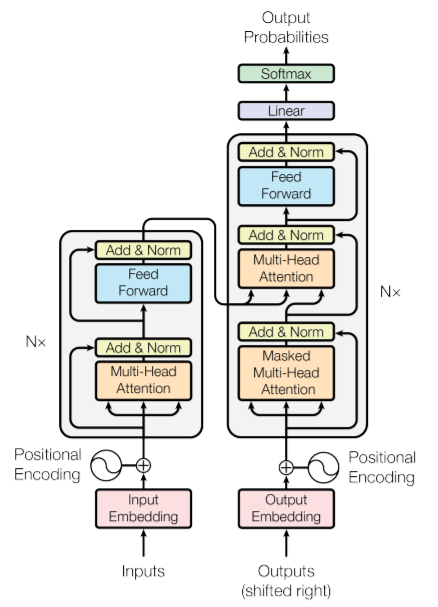
그래서 encoder self attention에서는 encoder input(input embedding)의 learned representation을 산출하도록 하고 decoder self attention에서는 decoder input(=shifted right output의 embedding)의 learned representation을 산출하도록 하고 encoder decoder attention은 encoder output & decoder output의 연관성을 반영한 learned representation을 산출한다
자연어처리 뿐 아니라 이미지(이미지의 해상도 높히기), 음악(앞부분을 들려주면 뒷부분을 생성하도록) 분야에서도 transformer가 사용된다