[모두를 위한 딥러닝2 Pytorch] Logistic Regression
🍳 reference: <모두를 위한 딥러닝 2: pytorch> Lab5
logistic regression의 경우에도, 이론은 정리해 두었으니 pytorch 식 위주로 살펴보자
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
Hypothesis
예를 들어, data X가 (m개의 sample, d차원) 있을때,
이를 바탕으로 0과 1로 이루어진 m개의 정답들을 predict 해야한다.
(이와 같은 binary classification의 경우 1일 확률과 0일 확률의 합은 1이 된다)
Cost function
이때 y가 H(x)와 비슷할수록 cost funtion이 0에 가깝다.
마지막으로 sigmoid 함수를 통해 binary classification을 완료한다
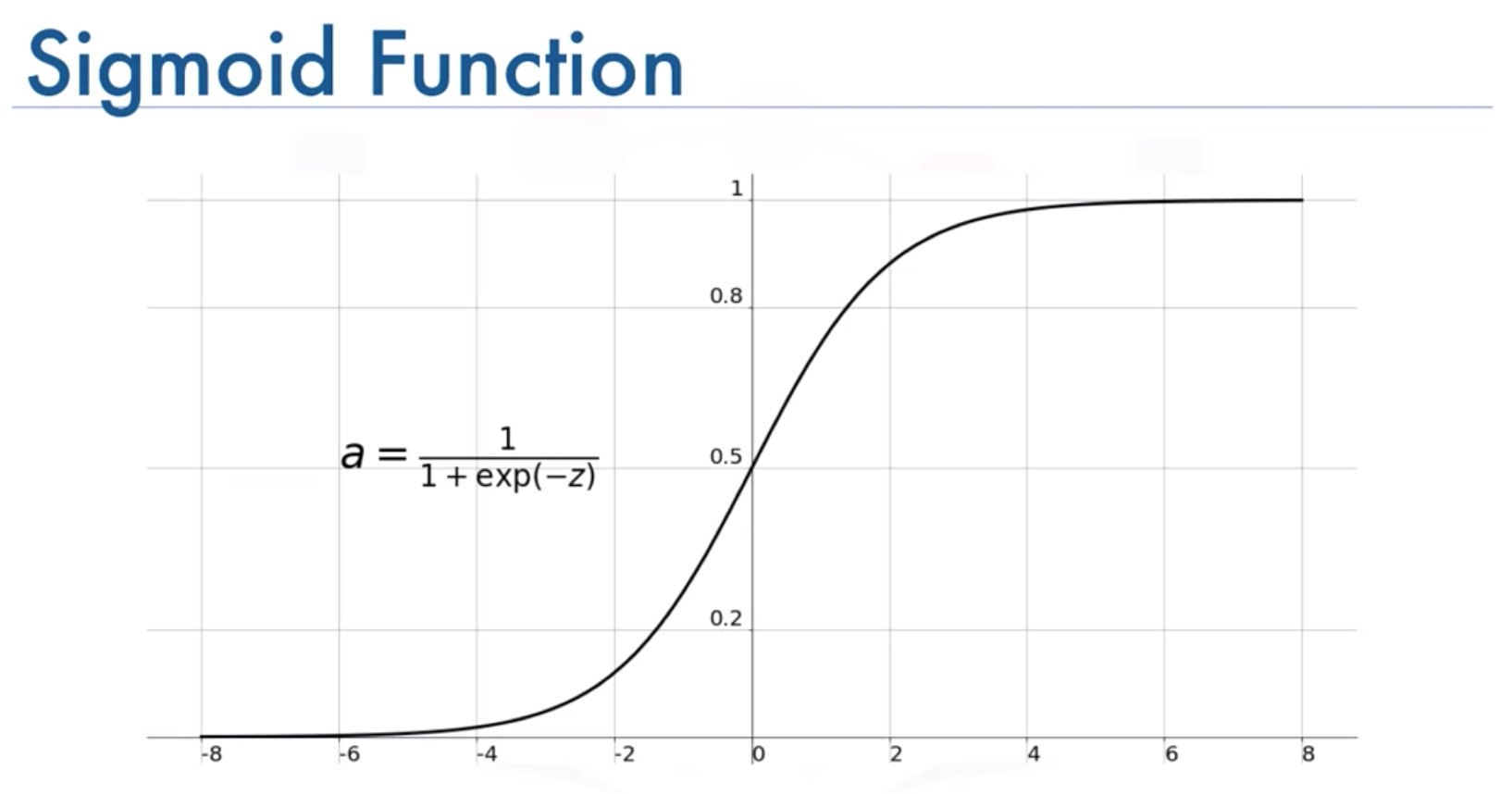
code는 아래와 같다
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]] # (6,2)의 데이터
y_data = [[0], [0], [0], [1], [1], [1]] # (6,)의 데이터
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
# 모델 초기화
W = torch.zeros((2, 1), requires_grad=True) # zero gradient로 꼭 초기화 해줘야 함
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# Cost 계산 - sigmoid 이용
hypothesis = torch.sigmoid(x_train.matmul(W) + b) # or .mm or @
cost = -(y_train * torch.log(hypothesis) +
(1 - y_train) * torch.log(1 - hypothesis)).mean()
# cost로 H(x) 개선 - backpropagation
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
또는 cost = F.binary_cross_entropy(hypothesis, y_train) 를 대신 써서 binary_cross_entropy를 계산할수도 있다.
Evaluation
아래와 같이 성능을 평가할 수 있다.
hypothesis = torch.sigmoid(x_train.matmul(W) + b)
prediction = hypothesis >= torch.FloatTensor([0.5])
correct_prediction = prediction.float() == y_train
accuracy = correct_prediction.sum().item() / len(correct_prediction)
print('The model has an accuracy of {:2.2f}% for the training set.'.format(accuracy * 100))
module.nn을 이용하면 아래와 같다
class BinaryClassifier(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))
위와 같은 경우, W는 (8,1)이고, b = (8,) 임을 알 수 있다
즉, m의 값은 모르지만 d는 8인 것이당
model = BinaryClassifier()
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1)
nb_epochs = 100
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = model(x_train)
# cost 계산
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 10 == 0:
prediction = hypothesis >= torch.FloatTensor([0.5])
correct_prediction = prediction.float() == y_train
accuracy = correct_prediction.sum().item() / len(correct_prediction)
print('Epoch {:4d}/{} Cost: {:.6f} Accuracy {:2.2f}%'.format(
epoch, nb_epochs, cost.item(), accuracy * 100,
))