🍳 reference: <모두를 위한 딥러닝 2: pytorch> Lab10
이제 본격적으로 CNN 시작!
Convolution
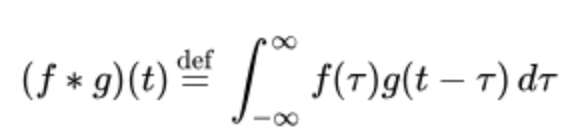
이미지 위에서 stride 만큼 filter를 이동시키면서 겹쳐지는 부분의 각 element 값을 곱해서 모두 더한 값을 출력으로 하는 연산을 의미한다.
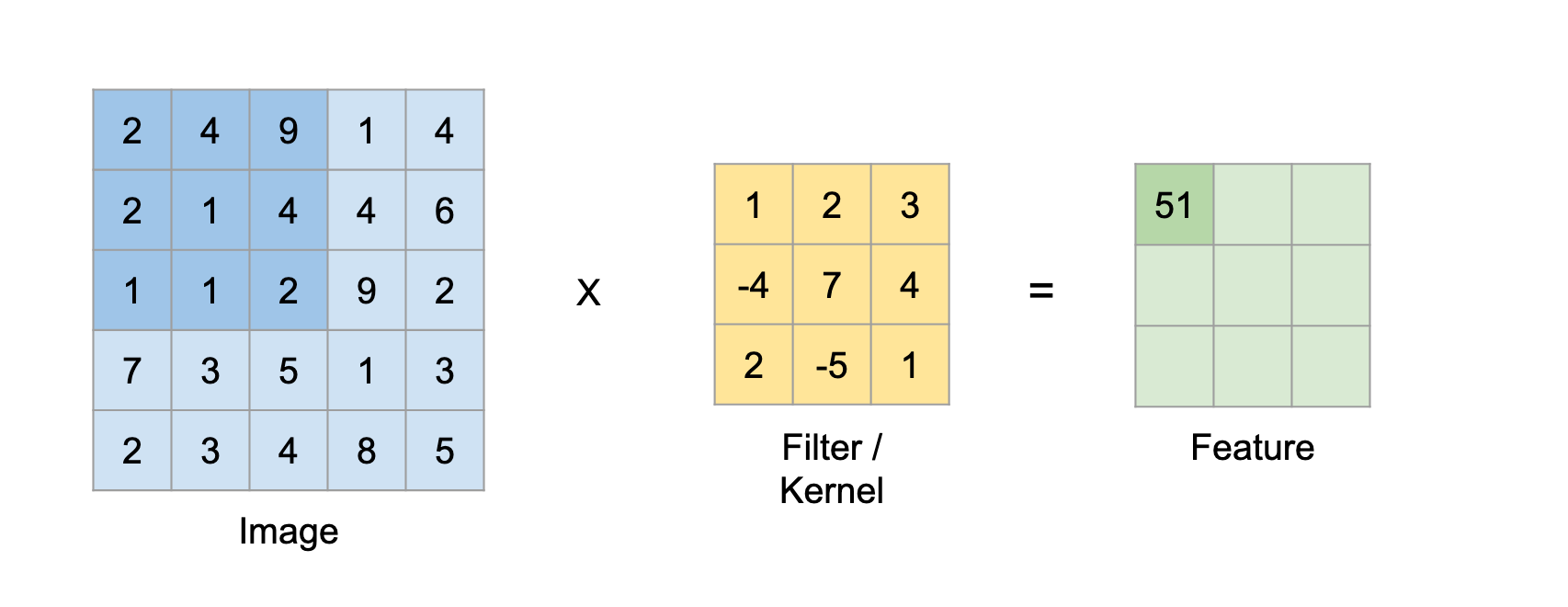
stride는 얼마나 filter를 이동할 것인지를, padding은 가장자리 연산의 손실을 막기 위해 상하좌우에 0으로 가득찬 pad를 채워주는 것을 의미한다.
사실 CNN의 기본 원리, 각 용어의 개념(kernel, padding, pooling, ..)들은 모모딥1에서 훨씬 자세하게 나와있고,
이번 모모딥 2에서는 pytorch 버전 위주로 공부했다.
import pytorch
conv = torch.nn.Conv2d(input_channel, output_channel, kernal_size, ...)
output = conv(input)
이 연산에서 input의 type은 torch.Tensor, input의 shape 은 (batch size, channel, height, width) 이다.

이때 output size = (input size - filter size + 2*padding)/stride + 1 이다.
만약 input size = 32x32, filter size(=filter size) = 5x5, stride = 1, padding = 2이면,
output size = (32-5+2*2)/1 + 1 = 31 이 된다.
import torch
conv = torch.nn.Conv2d(1,1,5,stride = 1, padding = 2)
inputs = torch.Tensor(1,1,32,32)
out = conv(inputs)
print(out.shape)
# torch.Size([1, 1, 32, 32])
만약 input size = 32x64, filter size = 5x5, stride = 1, padding = 0이면,
output size = 28x60 이 된다.
import torch
conv = torch.nn.Conv2d(1,1,5,stride = 1)
inputs = torch.Tensor(1,1,32,64)
out = conv(inputs)
print(out.shape)
# torch.Size([1, 1, 28, 60])
** CNN 에서는 Perceptron의 weight 값으로 filter가 적용된다. **

pooling도 아래와 같이 사용할 수 있다.
import torch
pool = torch.nn.MaxPool2d(kernal_size, stride, padding , ...)
이제 가장 간단한 CNN 모델을 만들어보자.
import torch
conv1 = torch.nn.Conv2d(1,1,2,stride = 1)
pool = torch.nn.MaxPool2d(2)
inputs = torch.Tensor(1,1,28,28)
out1 = conv1(inputs)
out2 = pool(out1)
out1.size() #torch.Size([1, 1, 27, 27])
out2.size() #torch.Size([1, 1, 13, 13])
MNIST 에 CNN을 적용하면 아래와 같다. click reference!
# Lab 11 MNIST and Convolutional Neural Network
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
# parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 100
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
# dataset loader
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
# CNN Model (2 conv layers)
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
# L1 ImgIn shape=(?, 28, 28, 1)
# Conv -> (?, 28, 28, 32)
# Pool -> (?, 14, 14, 32)
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# L2 ImgIn shape=(?, 14, 14, 32)
# Conv ->(?, 14, 14, 64)
# Pool ->(?, 7, 7, 64)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# Final FC 7x7x64 inputs -> 10 outputs
self.fc = torch.nn.Linear(7 * 7 * 64, 10, bias=True)
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1) # Flatten them for FC
out = self.fc(out)
return out
# instantiate CNN model
model = CNN().to(device)
# define cost/loss & optimizer
criterion = torch.nn.CrossEntropyLoss().to(device) # Softmax is internally computed.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# train my model
total_batch = len(data_loader)
print('Learning started. It takes sometime.')
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
print('Learning Finished!')
# Test model and check accuracy
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
tensorflow의 경우에는 아래와 같다. click reference
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import os
tf.enable_eager_execution()
## Hyper Parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 100
##Creating a Checkpoint Directory
cur_dir = os.getcwd()
ckpt_dir_name = 'checkpoints'
model_dir_name = 'minst_cnn_seq'
checkpoint_dir = os.path.join(cur_dir, ckpt_dir_name, model_dir_name)
os.makedirs(checkpoint_dir, exist_ok=True)
checkpoint_prefix = os.path.join(checkpoint_dir, model_dir_name)
## MNIST Dataset
mnist = keras.datasets.mnist
class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
## Datasets
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.astype(np.float32) / 255.
test_images = test_images.astype(np.float32) / 255.
train_images = np.expand_dims(train_images, axis=-1)
test_images = np.expand_dims(test_images, axis=-1)
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(
buffer_size=100000).batch(batch_size)
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(batch_size)
## Model Function
def create_model():
model = keras.Sequential()
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, activation=tf.nn.relu, padding='SAME',
input_shape=(28, 28, 1)))
model.add(keras.layers.MaxPool2D(padding='SAME'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, activation=tf.nn.relu, padding='SAME'))
model.add(keras.layers.MaxPool2D(padding='SAME'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, activation=tf.nn.relu, padding='SAME'))
model.add(keras.layers.MaxPool2D(padding='SAME'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(256, activation=tf.nn.relu))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10))
return model
model = create_model()
## Loss Function
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits, labels=labels))
return loss
## Calculating Gradient
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
## Caculating Model's Accuracy
def evaluate(model, images, labels):
logits = model(images, training=False)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
## Optimizer
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
## Creating a Checkpoint
checkpoint = tf.train.Checkpoint(cnn=model)
# train my model
print('Learning started. It takes sometime.')
for epoch in range(training_epochs):
avg_loss = 0.
avg_train_acc = 0.
avg_test_acc = 0.
train_step = 0
test_step = 0
for images, labels in train_dataset:
grads = grad(model, images, labels)
optimizer.apply_gradients(zip(grads, model.variables))
loss = loss_fn(model, images, labels)
acc = evaluate(model, images, labels)
avg_loss = avg_loss + loss
avg_train_acc = avg_train_acc + acc
train_step += 1
avg_loss = avg_loss / train_step
avg_train_acc = avg_train_acc / train_step
for images, labels in test_dataset:
acc = evaluate(model, images, labels)
avg_test_acc = avg_test_acc + acc
test_step += 1
avg_test_acc = avg_test_acc / test_step
print('Epoch:', '{}'.format(epoch + 1), 'loss =', '{:.8f}'.format(avg_loss),
'train accuracy = ', '{:.4f}'.format(avg_train_acc),
'test accuracy = ', '{:.4f}'.format(avg_test_acc))
checkpoint.save(file_prefix=checkpoint_prefix)
print('Learning Finished!')
아래와 같은 functional model도 가능하다. click reference!
sequential에서와 모델 생성 외에는 동일하다
def create_model():
inputs = keras.Input(shape=(28, 28, 1))
conv1 = keras.layers.Conv2D(filters=32, kernel_size=[3, 3], padding='SAME', activation=tf.nn.relu)(inputs)
pool1 = keras.layers.MaxPool2D(padding='SAME')(conv1)
conv2 = keras.layers.Conv2D(filters=64, kernel_size=[3, 3], padding='SAME', activation=tf.nn.relu)(pool1)
pool2 = keras.layers.MaxPool2D(padding='SAME')(conv2)
conv3 = keras.layers.Conv2D(filters=128, kernel_size=[3, 3], padding='SAME', activation=tf.nn.relu)(pool2)
pool3 = keras.layers.MaxPool2D(padding='SAME')(conv3)
pool3_flat = keras.layers.Flatten()(pool3)
dense4 = keras.layers.Dense(units=256, activation=tf.nn.relu)(pool3_flat)
drop4 = keras.layers.Dropout(rate=0.4)(dense4)
logits = keras.layers.Dense(units=10)(drop4)
return keras.Model(inputs=inputs, outputs=logits)
model = create_model()