[ML/DL] Decision Tree - 핸즈온 머신러닝 Chap 6
Definition
의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종이다. (스무고개랑 비슷한 느낌)
random forest의 기본 구성 요소이기도 하다.
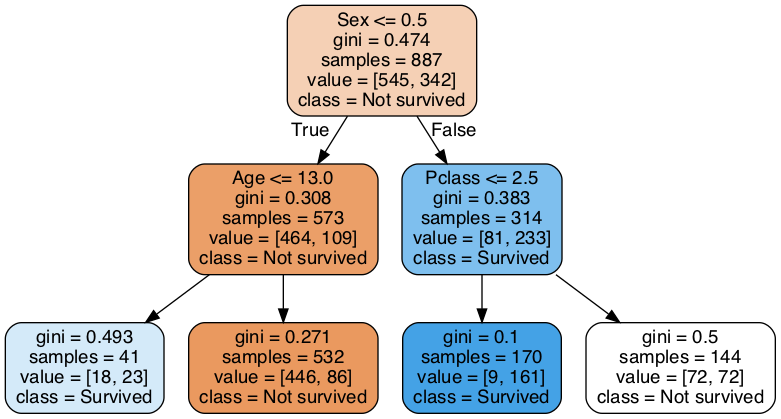
tree이기 때문에 node와 leaf를 가지고 있으며, root node에는 분류력이 좋은 기준을 채택하는 것이 좋다
impurity(불순도)
하나의 node에 class label이 혼재되어 있는 정도를 의미하며, impurity가 낮을수록 분류가 잘 되어있다는 뜻
entropy, gini index, cost function 등으로 측정한다.
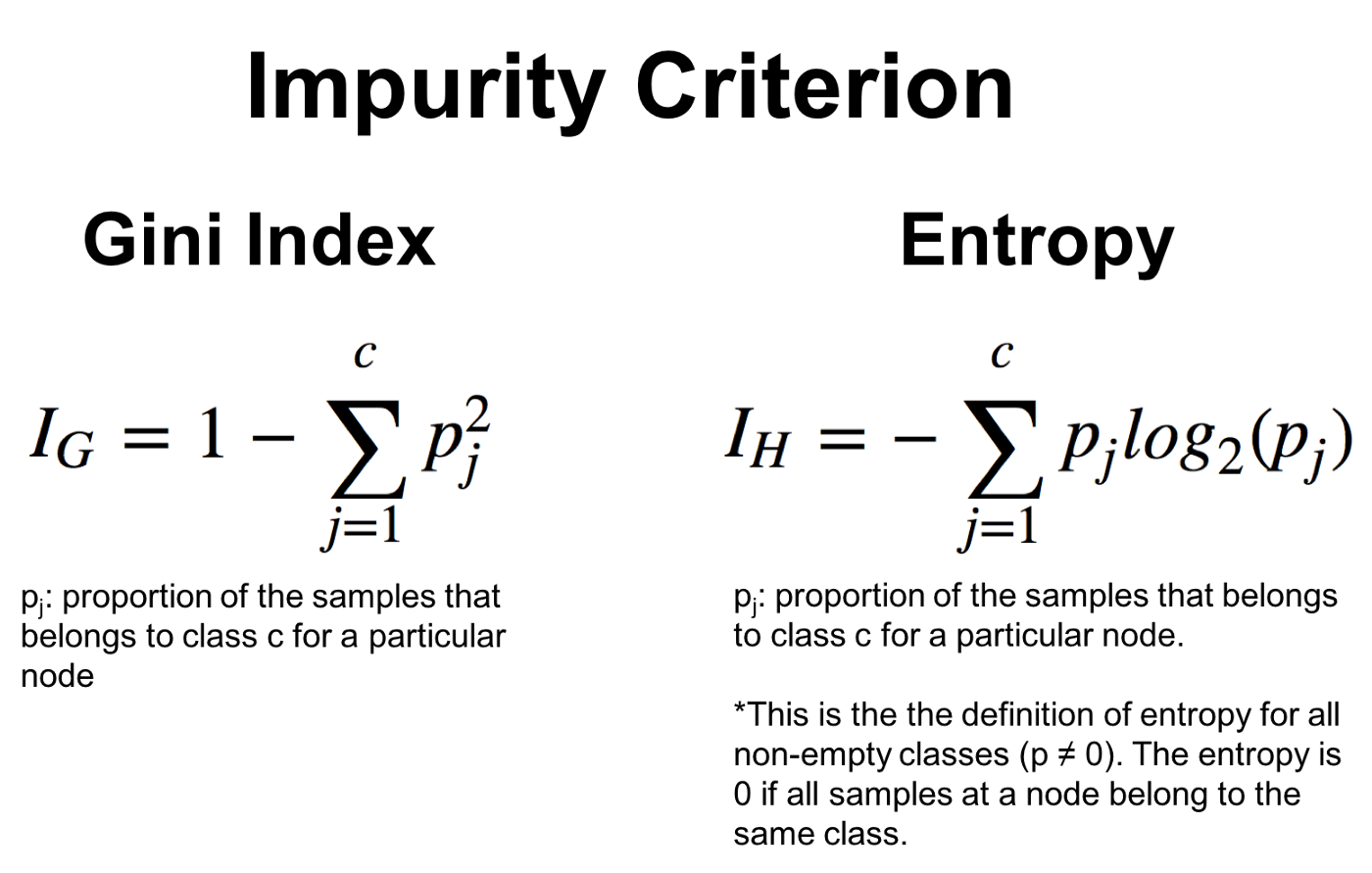
sklearn.tree.DecisionTreeClasifier를 이용하여 간단하게 진행할 수 있다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # 꽃잎 길이와 너비
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X, y)
이를 바탕으로, 한 sample이 특정 class (k)에 속할 확률을 추정할 수 있다.
(가장 높은 확률의 class에 속한다고 판단하는 것이다)
tree_clf.predict_proba([[5, 1.5]])
tree_clf.predict([[5, 1.5]])
sklearn에서는 decision tree의 훈련을 위해 CART(Classification And Regression Tree) 알고리즘을 사용한다.

이렇게 하나의 training set를 반으로 나누고, 같은 방식으로 subset을 나누고, .. 하는 과정을 반복한다.
최대 깊이가 되거나, impurity를 줄일 수 없을 때 중단한다.