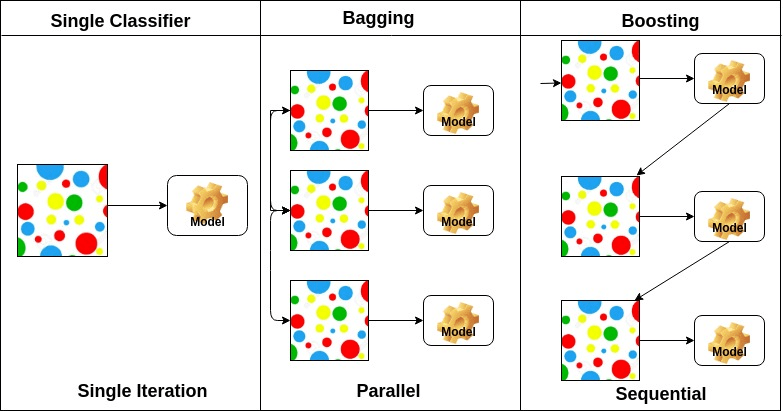
Ensemble
더 좋은 예측 성능을 얻기위해 다수의 학습 알고리즘을 사용하는 방법.
예를 들어 training set으로부터 무작위로 각기 다른 subset을 만들어 decision tree를 훈련시킨 후
가장 많은 선택을 받은 class를 예측으로 삼는 것.
예측기가 가능한 한 서로 독립적일 때 최고의 성능을 발휘한다다.
왜나하면 매우 다른 종류의 오차를 만들 가능성이 높기 때문에 앙상블 모델의 정확도를 향상시키기 때문이다.
ensemble model은 다양한 유형이 있는데,
아래와 같이 다른 훈련 알고리즘을 사용하거단,
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)
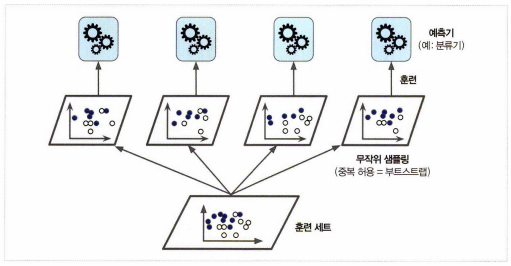
같은 알고리즘을 사용하지만 training set의 subset을 무작위로 구성하여
각 예측기를 다르게 학습 시키는 방법이다.
중복을 허용하여 sampling하면 bagging, 허용하지 않고 sampling하면 pasting이라고 한다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
BaggingClassifier는 기본값으로 중복을 허용하여(bootstrap=True) 훈련 세트의 크기만큼인 m개 샘플을 선택한다.
(평균적으로 각 예측기에 훈련 샘플의 63% 정도만 샘플링됨)
선택되지 않은 훈련 샘플의 나머지 37%를 oob(out-of-bag) 샘플이라고 부릅니다. (예측기마다 남겨진 37%는 모두 다름)
예측기가 훈련되는 동안에는 oob 샘플을 사용하지 않으므로 별도의 검증 세트를 사용하지 않고 oob 샘플을 사용해 평가할 수 있다.
(이떄, ensemble model 의 평가는 각 예측기의 oob 평가를 평균하여 얻음)
sklearn.BaggingClassifier에서 oob_score=True로 지정하면 훈련이 끝난 후 자동으로 oob 평가를 수행해준다.
또한 max_features, bootstrap_features로 feature도 sampling이 가능하다.
Random forest
Decision Tree의 ensemble을 random forest라고 한다.
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes =16, n_jobs=-1)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
Extra Tree
random forest중에서 극단적으로 random인 tree의 random forest를 의미한다.
bias는 늘어나지만 variance가 낮아지고, 시간이 빠르다.
일반적으로 sklearn.ensemble.ExtraTreesClasifier를 사용하며,
항상 random forest보다 성능이 낫다고 할 수는 없으므로 둘다 사용하여 비교하는 것이 좋다.
feature importance (특성 중요도)
random forest를 통해 각 feature의 상대적 중요도를 확인할 수 있다.
from sklearn.datasets import load_iris
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)
boosting
여러 모델을 연결해가며 학습하는데, 이때 아퓨의 모델을 보완해가며 일련의 예측기를 학습하는 것이다.
이를 통해 약한 학습기를 여러개 연결하여 강한 학습기를 만들 수 있다.
AdaBoost
이전 모델이 underfitting 이었던 training sample의 weight을 더 높이느 ㄴ것이다.
gradient descent랑 조금 비슷한데, gradient descent는 cost function을 최소화하기 위해 예측기의 모델 parameter를 조절하는 반면
Adaboost는 좋아지도록 ensemble에 예측기를 추가한다.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5)
ada_clf.fit(X_train, y_train)
Gradient Boost
이전 모델의 오차를 보정하도록, 이전 예측기가 만든 residual error에 새로운 예측기를 학습시킨다.
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
gbrt.fit(X, y)
stacking
stacked generalization의 줄임말로, ensemble에 속한 모든 예측기의 예측을 취합하는 모델이다.
이때 취합하는 마지막 예측기는 blender또는 meta learner라고 한다.
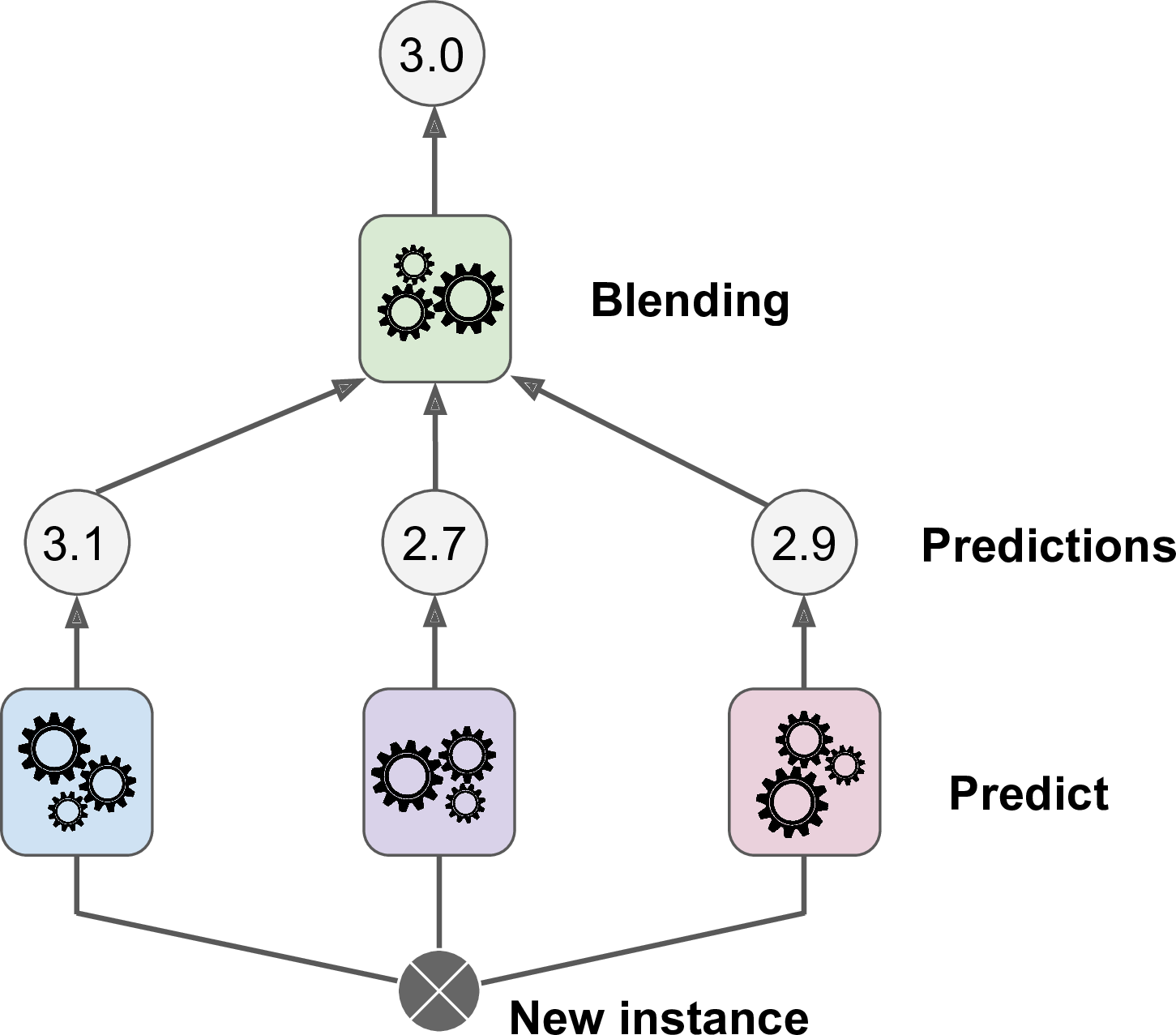
blender를 학습시키는 일반적인 방법은 hold-out set를 사용하는 것이다.