[NLP] Dependency Parser
Dependency parsing 이란, 단어들의 관계를 통해 의미 구조를 파악하는 것이다.

언어에 상관없이 {subject, predicate, object}를 추출 문장의 의미 구조를 파악할 수 있다.
Dependency parsing은 크게 두가지로 나뉘는데,
문장이 가질 수 있는 모든 의존트리(dependencytree)중에서 가장 높은 점수의 의존트리를 선택하는 방법인 non-deterministic dependency parsing,
greedy algorithm에 기반한 방법으로 locally training model을 사용하는 deterministic dependency parsing이 있다.
후자의 경우 더 많은 문맥자질을 사용할 수 있고, 근거리 의존관계를 찾는데 강하며, 속도가 빠른 장점을 가지고 있다
한국어의 경우, Sejong Treebank를 바탕으로 하는 선행 연구가 있었다.
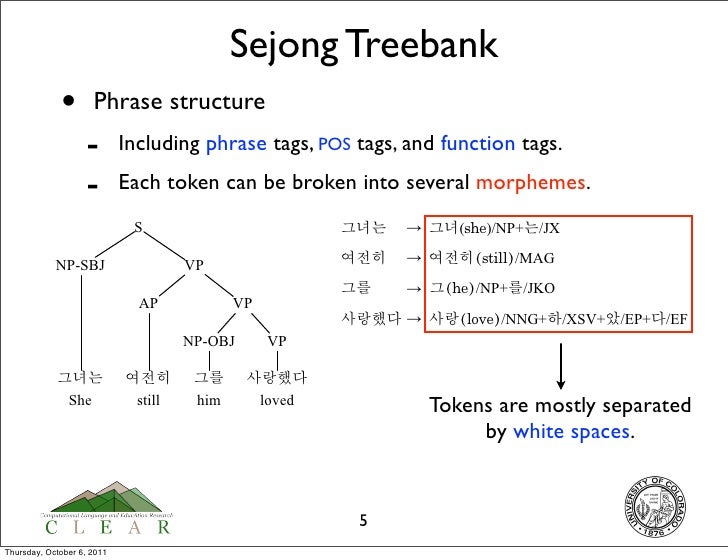
이처럼 형태소 tagging을 바탕으로 진행하며, koalanlp에서 간단한 예시를 테스트해볼 수 있다.
from koalanlp.Util import initialize, finalize
from koalanlp import API
from koalanlp.proc import Parser
initialize(hnn='LATEST')
parser = Parser(API.HNN) # 또는 API.KKMA, API.ETRI
# ETRI 분석기의 경우 API 키를 필수적으로 전달해야 합니다. 예: Parser(API.ETRI, etri_key=API_KEY)
parsed = parser("이 문단을 분석합니다. 문단 구분은 자동으로 합니다.")
# 또는 parser.analyze(...), parser.invoke(...)
# 첫번째 문장의 의존구조를 출력합니다.
for dep in parsed[0].getDependencies():
print(dep)
# 첫번째 문장의 구문구조 트리를 출력합니다.
print(parsed[0].getSyntaxTree().getTreeString())
Reference
-
https://gnoej671.tistory.com/5
-
https://nlp100.github.io/en/ch05.html
-
https://www.slideshare.net/jchoi7s/statistical-dependency-parsing-in-korean-from-corpus-generation-to-automatic-parsing