1. word embedding
one-hot encoding

-
vocab size V 에 대해, one-hot vector v는 $𝑣 ∈ 0,1^V$ → 이에 따라, 차원의 수가 매우 큼 [curse of dimensionality]
→ Information quality 낮아짐 , Memory use↑, Computation time ↑
- curse of dimensionality
- 대부분 ML에서 data의 차원수가 높을때 문제 발생함
- 차원이 증가할수록, data가 급격하게 sparse해짐
- subspace 끼리의 combination조합도 기하급수적으로 증가함
→ 이를 해결하기 위한 차원축소: PCA, LDA
- data distribution을 가장 잘 설명해주는 2개의 axis로 데이터를 나타내는 PCA
- 대부분 ML에서 data의 차원수가 높을때 문제 발생함
- manifold hypothesis
- 고차원의 natural data로부터, 저차원의 manifold를 찾자 !
- 수학적으로 증명되지 않는 assumption에서 발견됨
- 실제 data는 uniform한 분포가 아니고, nonlinear pattern임
-
이 manifold는 original space에서 찾기 힘듦 : nonlinear해서, nonlinear activation 사용해야함
→ 복잡한 nonlinear사이에 linear가 포함되어 있기 때문에, NN에서 linear와 nonlinear function을 번갈아가면서 사용함
-
-
how to capture manifold?
→ autoencoder 사용

- goal: input data의 low dimensional representation 찾기
- bottleneck은, feature가 합쳐진 형태임
- bottleneck vector를 사용하는 이유? : 단순히 data 분석을 하기 위해서 or 모든 network를 학습하려면 data가 엄청 많이 필요한데, 효과적인 학습을 위해
- challenge를 주기 위한 bottleneck 즉 너무 크기가 너무 작으면 안됨
- encoder: 고차원의 input을 저차원으로 translation
- decoder: data를 recover하여 input data와 동일한 크기로 만듦
- loss function: MSE 사용 (reconstruction error) : 즉 original data와 manifold plane에서의 좌표(즉 encoded input)사이의 유클리디언 거리
- goal: input data의 low dimensional representation 찾기
→ 따라서, one-hot embedding에 autoencoder를 적용하면??
→ 더 dense해지고, informative해짐
Word Embedding: Word2Vec
- Distributional Hypothesis : Words that occur in similar contexts tend to be similar
- unsupervised method임
- CBOW, Skipgram 등등
-
전체 normalization factor를 다 계산하면 너무 expensive함
→ 이를 보완하기 위한 다양한 techniques
- hierarchical softmax : word 를 tree로 구성해보면, 적절한 단어를 찾는 과정이 binary search임 → log scale로 computational expense 감소
- negative sampling : random하게 sampling해도 확률 분포 유추 가능
Word2Vec:CBOW
-
Continuous Bag of Words (CBOW)
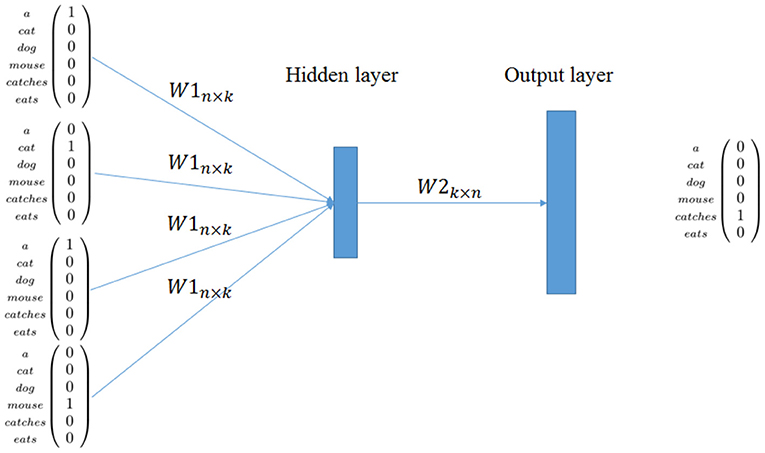
- goal: 주어진 neighboring words (contexts)로부터, context 정황상 적절하게 들어갈 것 같은 single words를 predict
- Input: a set of one-hot vectors of given context words
- 위 그림에서, n x k의 W1는 learnable parameter임
- k : the number of words in vocabulary (hyperparameter)
- n : the size of hidden representation (hyperparameter)
- 위 그림에서, n x k의 W1는 learnable parameter임
-
각 W1은 k x 1차원의 vector와 곱해져, hidden layer의 representation이 됨
→ one-hot vector는 거의 0이라서, 1이랑 곱해지는 부분만 살아남음 (즉 해당되는 index의 값만 뽑아오는 것과 같음)
- encoder를 사용하여 input을 압축한 후 다시 decoder로
- cross-entropy loss function
-
output은, 가장 적합한 word를 찾는 classification느낌임
→ 이렇게 word vocab으로 classification하는걸 language model이라고 함 !!
-
Word2Vec:Skip-gram
-
example sentence: the quick brown fox funs away

-
CBOW랑 거의 똑같음

CBOW vs Skip-gram
- 둘중에 skip-gram를 더 많이 사용함
- skip gram: 학습에 많은 시간이 필요함 & 적은 데이터로도 성능 좋음 & 희귀한 word,phase도 잘 예측함
- CBOW: 자주 사용하는 단어들에 대해 정확도가 더 높음
이전에 사용했던 방법들
- edit distance
- WordNet
Must-read papers
-
, 2013, archieved - similar word를 vector 공간에서 정의하는 것이 아니라 syntax, semantic 관점에서 정의 및 설명
- NNLM(Feedforward neural net language model) 모델 제안
-
, 2013, neurips - skip-gram의 vector representation quality를 향상하기 위한 3가지 방법 제안
- <GloVe: Global Vectors for Word Representation>, 2014, EMNLP
- global word-word-co-occurrence count 를 이용 즉 전체 corpus에 대한 통계적인 정보를 모두 담고 있는 모델인 GloVE제안
Supplementary readings
Reference
- 연세대학교 여진영 교수님의 ‘AAI5003: 자연어처리를 위한 딥러닝’ , 2022년 1학기
- figures
- [https://miro.medium.com/max/560/1g1yE9fEP6pB2Yn5vUUxOTw.png](https://miro.medium.com/max/560/1g1yE9fEP6pB2Yn5vUUxOTw.png)
- [https://miro.medium.com/max/1400/1ggtP4a5YaRx6l09KQaYOnw.png](https://miro.medium.com/max/1400/1ggtP4a5YaRx6l09KQaYOnw.png)
- https://www.researchgate.net/profile/Wang-Ling-16/publication/281812760/figure/fig1/AS:613966665486361@1523392468791/Illustration-of-the-Skip-gram-and-Continuous-Bag-of-Word-CBOW-models.png
- https://www.frontiersin.org/files/Articles/458535/frobt-06-00153-HTML/image_m/frobt-06-00153-g001.jpg