두번째로 정리해볼 논문은 2019년 상반기에 나온
Text Classification Algorithms: A Survey
이다. 다른 NLP(text feature extractions, dimensionality reduction method, …)와는 다른 text classification의 특징 등을 담은 review paper 이다.
따로 github 링크도 달아두셔서 공부하기도 세상 편했던 !!!
Index
-
Introduction
-
Text preprocessing
-
Text cleaning & pre-processing
-
syntactic word representation
-
weighted words
-
word embedding
-
-
dimensionality reduction
-
Component Analysis
-
Linear Discriminant Analysis (LDA)
-
Non-negative matrix factorization (NMF)
-
Random projection
-
Autoencoder
-
t-SNE
-
-
Existing Classification Techniques
-
Rocchio Classification
-
Boosting & Bagging
-
Logistic Regression
-
Naiive Bayes Classifier
-
K-Nearest Neighborhood
-
Support Vector Machine (SVM)
-
Decision Tree
-
Random Forest
-
Conditional Random Field (CRF)
-
Deep learning
-
Semi-Supervised Learning for Text Classification
-
-
Evaluation
-
Macro-Averaging and Micro-Averaging
-
Fβ score
-
Matthews Correlation Coefficient (MCC)
-
Receiver Operating Characteristics (ROC)
-
Area Under ROC Curve (AUC)
-
-
Discussion
-
Text and Document Feature Extraction (about section 2)
-
Dimentionality reduction (about section 3)
-
Existing classification Techniques (about section 4)
-
Evaluation (about section 5)
-
-
Text classification Usage
-
text classification applications
-
text classification support
-
-
Conclusion
index만 보더라도, 전반적인 text classification을 잘 설명해줄 수 있을 것 같아 골랐다
이미 아는 내용도 많긴 하지만, 쭉 보면서 정리하고 싶은 애들은 아래에 추가적으로 적어나가기로 했다!
그러다가 의문이 생기면 citated paper 도 차근차근 따라가는거지 뭐!
[2] Text preprocessing
모든 데이터 사이언스, 특히 NLP 에서 제일 중요한 preprocessing!
1. Text cleaning & pre-processing
- tokenization진행
- e.g. After sleeping for four hours, he decided to sleep for another four.
- > `'After', 'sleeping', 'for', 'four', 'hours', 'he', 'decided', 'to', 'sleep' ,'for', 'another' ,'four'`
-
stop words, noise 제거
-
capitalization
-
slang & abbreviation(약어) 제거
-
spelling correction
- `context-sensitive spelling correction` , `Trie and Damerau-Levenshtein distance bigram`
- Stemming
- e.g. studying -> study
- 사전에 없는 어간을 추출하기도 함
- Lemmatization (표제어 추출)
- 사전에 있는 어간만 추출함
- [stemming과 Lemmatization의 차이](https://m.blog.naver.com/PostView.nhn?blogId=vangarang&logNo=220963244354&proxyReferer=https:%2F%2Fwww.google.com%2F)
2. syntactic word representation
- N-gram
- 단어들의 순서에 따라 n개의 단어 묶음으로 자름
- e.g. After sleeping for four hours, he decided to sleep for another four.
- 2-grams
- “After sleeping”, “sleeping for”, “for four”, “four hours”, “four he” “he decided”, “decided to”,
“to sleep”, “sleep for”, “for another”, “another four”
- 3-grams
- “After sleeping for”, “sleeping for four”, “four hours he”, “ hours he decided”, “he decided to”,
“to sleep for”, “sleep for another”, “for another four”
3. weighted words
- Bag Of Words (
BoW)
-
단어들의 순서는 전혀 고려하지 않고, 단어들의 frequency에만 집중한다.
-
각 단어에 고유한 정수 인덱스를 부여한 후, 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만든다.
-
e.g. “As the home to UVA’s recognized undergraduate and graduate degree programs in systems engineering. In the UVA Department of Systems and Information Engineering, our students are exposed to a wide range of range
-
{“As”, “the”, “home”, “to”, “UVA’s”, “recognized”, “undergraduate”, “and”, “graduate”, “degree”, “program”, “in”, “systems”, “engineering”, “in”, “Department”, “Information”,“students”, “ ”,“are”, “exposed”, “wide”, “range” }
-
Feature = {1,1,1,3,2,1,2,1,2,3,1,1,1,2,1,1,1,1,1,1}
-
limitations
-
단어의 양이 많아지면 연산이 무작정 늘어남 (확장성 문제)
-
문맥적 의미 고려 x (is this an apple과 this is an apple이 동일한 의미 갖게 됨 )
-
- Term Frequency - Inverse Document Frequency (
TF-IDF)
-
단어의 빈도(term frequency)와 역 문서 빈도(inverse document frequency)를 사용하여, DTM(Document-Term Matrix) 내의 각 단어들마다 중요한 정도를 가중치로 줌
-
DTM을 만든 후, TF-IDF 가중치를 부여함
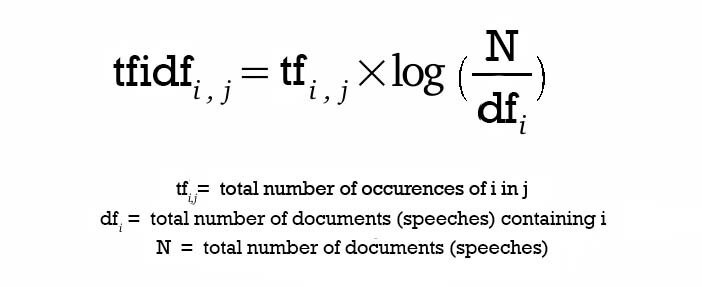
-
분모에 1을 더하는 이유: 특정 단어가 전체 문서에서 아예 등장하지 않으면 분모가 0이 되는 상황을 막기 위해
-
log를 취하는 이유-
n/df(t)를 바로 사용한다면 총 문서수 n이 커질수록 IDF가 기하급수적으로 커지게 됨 -
자주 쓰이는 단어들(불용어 등)은 자주 쓰이지 않는 단어들보다 최소 수십 배 ~ 수백배 자주 등장한다. 로그를 씌우면 가중치 격차를 를 줄일 수 있다.
-
-
BoW의 한계는 극복했지만, 문맥적으로 유사한 의미를 갖는 단어는 감지하지 못함
4. word embedding
Word embedding은 각 word 또는 phrase 가 N 차원 벡터에 mapping 되는 것이다.
일반적으로는 embedding vector 를 처음부터 만드는 것 보다, Pre-trained Word Embedding을 갖고 와서 사용하거나, 갖고 온 것에 추가 학습을 하는 방식으로 사용한다.
- Word2Vec
-
단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화 할 수 있는 방법
- 기존 one-hot vector가
sparse representation였던 것에 비해, Word2Vec은distributed representation을 이용하여 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가지게끔 단어의 유사도를 벡터화한다.
- 기존 one-hot vector가
-
종류
-
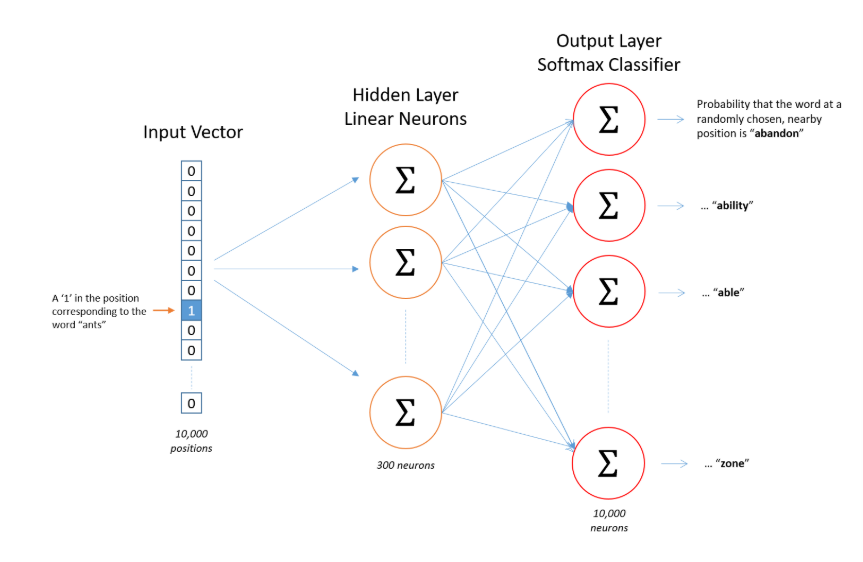
Skip-grams

-
중심 단어에서 주변 단어를 예측
-
전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있음
-
-
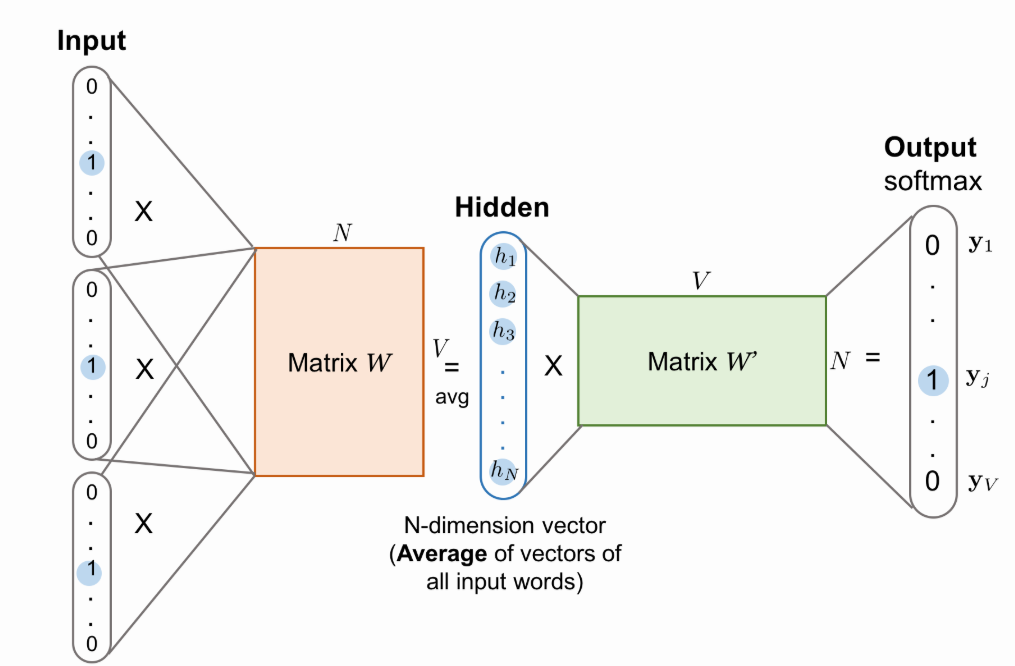
CBOW (Continuous Bag of Words)

-
주변 단어를 통해 중심 단어를 예측
-
학습시킬 문장의 모든 단어들을 one-hot encoding방식으로 벡터화한 후, 하나의 center 단어에 대해 2m개의 단어 벡터를
Input으로 하여, 주변의 단어들이 주어졌을 때 다음의 center 단어의 조건부 확률을 최대화 하도록 학습한다.- 이때 input에서의 embedded word vector 2m개의 평균을 계산한 벡터가
Hidden layer가 된다.
- 이때 input에서의 embedded word vector 2m개의 평균을 계산한 벡터가
-
unordered collection of words을 벡터로 표현하는 데 사용
-
-
Continuous Skip-Gram
-
문맥을 기반으로 현재 단어를 예측하지 않고, 동일한 문장에서 다른 단어를 기반으로 단어의 classification를 최대화하도록 한다.
-
CBOW model과 continuous Skip-gram model은, ML 알고리즘을 위해 문장의 구문 및 의미 정보를 유지하는 데 사용한다.
-
-
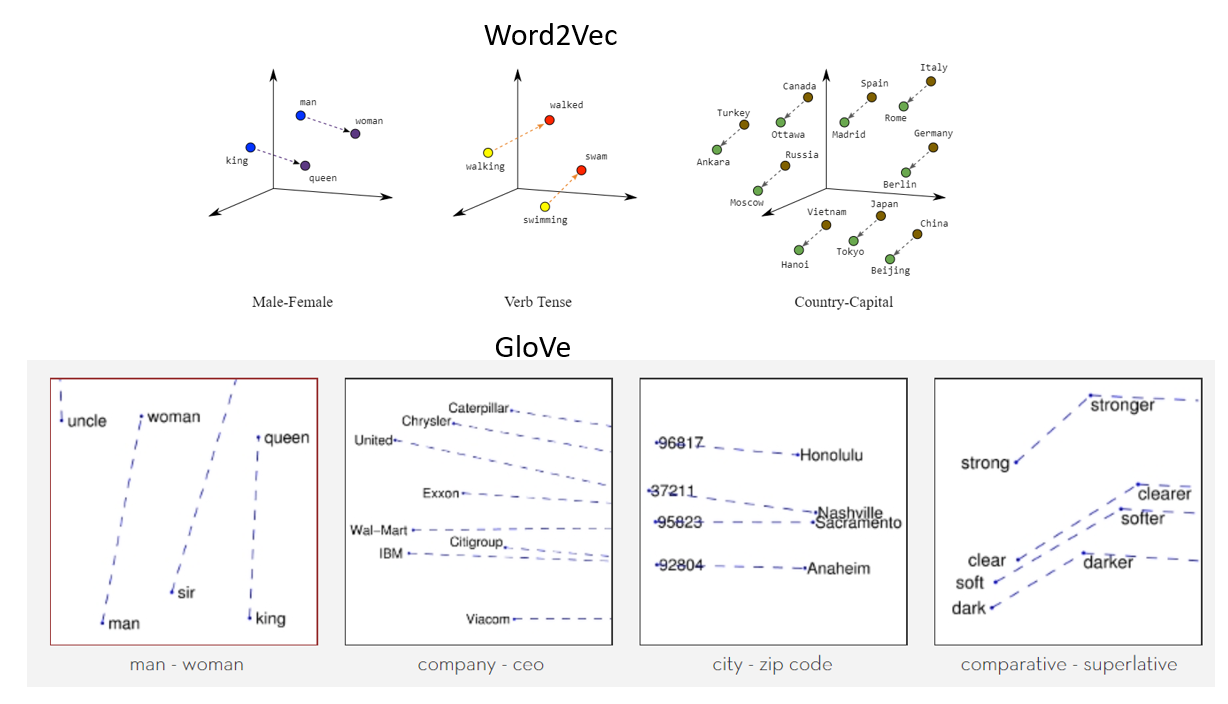
- Global Vectors for Word Representation (
GloVe)
-
word2vec과 비슷하지만, Word2Vec이 사용자가 지정한 윈도우(주변 단어 몇개만 볼지) 내에서만 학습/분석이 이뤄지기 때문에, 말뭉치 전체의 공기정보(
co-occurrence)는 반영되기 어렵다는 단점을 보완하고자 하였다. -
임베딩된 inner product가 코사인 유사도가 되도록 하며, 말뭉치 전체의 통계 정보를 좀 더 잘 반영해보게끔 하였다.
-
또한 100, 200, 300 차원으로 사전 훈련된 다른 단어 vectorization를 제공한다 (Twitter내용을 포함하는 거대한 말뭉치)
- FastText
-
우선 모르는 단어, 즉
Out Of Vocabulary에 대해 각 단어를 글자들의 n-gram으로 나타낸다.-
e.g. apple, n=3 -> <ap, app, ppl, ple, le>,
-
이떄 n은 설정가능하지만, 기본적으로는 3,6이다.
-
-
이후 학습을 통해 dataset의 모든 단어의 각 n-gram에 대해서 word embedding 한다. 이를 통해 내부 단어(subword)를 통해 모르는 단어(OOV)에 대해서도 다른 단어와의 유사도를 계산할 수 있다.
-
등장 빈도 수가 적은 단어라 하더라도, n-gram으로 임베딩을 하는 특성상 참고할 수 있는 경우의 수가 많아지므로 Word2Vec보다 정확하다
- 오타 등 noise가 섞인 단어는 당연히 등장 빈도수가 매우 적으므로 일종의 희귀 단어가 된다. Word2Vec에서는 이러한 단어는 임베딩이 제대로 되지 않지만 FastText는 이에 대해서도 나쁘지 않은 성능을 보인다
- Contextualized Word Embedding
-
ELMO(Embeddings from Language Models)를 설명하는 내용이다.
- ELMO는 방대한 text corpus로부터 pretrained된 Our word vector이며, deep bidirectional language model(
biLM)로부터 학습된다.
- ELMO는 방대한 text corpus로부터 pretrained된 Our word vector이며, deep bidirectional language model(

-
ELMO를 통해 같은 단어라도 문맥에 따라 다른 vector를 만들어낸다. 순방향 모델과 역방향 모델에서의 값을 합쳐 사용
- 순방향 모델
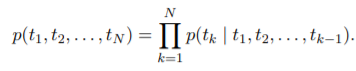
- 역방향 모델
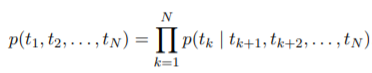
추가 Reference
-
TF-IDF
- https://blog.kakaocdn.net/dn/b73SmS/btqBtNyPGpT/G6RJlEJpc96OEMz18UnFr1/img.jpg
-
Word2vec
-
https://simonezz.tistory.com/35
-
https://wikidocs.net/22660
-
-
Glove
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/09/glove/
-
FastText
- https://omicro03.medium.com/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-nlp-15%EC%9D%BC%EC%B0%A8-fasttext-2b1aca6b3b56
-
ELMO
-
https://wikidocs.net/33930
-
https://medium.com/@eyfydsyd97/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-deep-contextualized-word-representations-3e227f57fa0d
-