2022.05.01 : 새롭게 정리한 페이지 참고(https://mydann.notion.site/All-about-Transformer-f40c9a796cc741debd633c27a92cf78e)
이번에 정리해볼 논문은,
Attention is All You Need
이다. 대부분의 sequence transduction model이 encoder와 decoder를 포함하고 있는 RNN, CNN을 기반으로 하는데,
이 논문에서는 attention mechanism 만을 바탕으로 하는 Transformer 구조를 제안한다.
성능이 좋고 시간이 단축되면서도 더 parallelizable하다.
번역에서 많이 쓰였던 기존 Seq2Seq-Attention model은 각각 자신의 언어(Souce Language, Targe Language)만에 대해서는 관계를 나타낼수 없었다.
(예를 들면 I love tiger but it is scare와 나는 호랑이를 좋아하지만 그것(호랑이)는 무섭다 사이의 관계는 매칭이 가능했지만,
it이 무엇을 나타내는지?와 같은 문제는 기존 Encoder-Decoder 기반의 Attention mechanism에서는 찾을 수 없었다.
Introduction
-
language modeling이나 translation 등에서 RNN, LSTM, GRNN 등이 SOTA를 기록해왔으며, recurrent language model과 encoder-decoder model의 경계가 허물어지고 있음
- recurrent model의 특징
- 주로 input&output sequence의 symbol position을 통해 factor computation을 진행함
- ..(RNN 특징이라 생략)
- 그러나 longer sequence에서 메모리 부족문제 등 여전히 한계점 존재함
- 구조의 특성상 sequential하기 때문에 parallelization을 방해
- but, sequence length가 길어질수록 memory limit 때문에 parallelization이 중요
- 우리는 Transformer 라는 model을 제안함
- recurrence를 피함 (recurrence model의 단점 가지지 않음)
- Attention mechanism 만을 사용함
-
Attention mechanism을 통해 input sequence와 output sequence의 거리에 무관하게 sequence modeling과 transduction model이 가능
- input과 output의 거리에 상관없이 modeling 가능 == 즉 global dependecy를 끌어냄
Background
- sequencial computation(즉 연산량)을 줄이기위한 노력 -Extened Neural GPU, ByteNet, ConvS2S 등등
- CNN을 basic building block(input&output position들의 hidden representation을 병렬적으로 계산)으로 사용
- input&output의 position으로부터 relate sigmal을 계산하기 위해 필요한 operation 개수가 증가하게 됨(COvS2에서는 선형적으로, ByteNet에서는 log적으로)
- 반면 Transformer에서는
- 연산의 수가 상수로 줄었음
-
attention-weighted position을 평균냄으로서 reduced effictive resolution을 얻었음
→ 그 결과로 multi-head attention을 맞았음
- self-attention(intra-attention)
- sequence의 representation을 얻기 위해 single sequence의 different position들을 연결짓는 attention mechanism임 (?)
- summarization, MRC 등 다양한 task에서 좋은 성능을 거둠
- end-to-end memory network
- sequence-aligned recurrence가 아니라 recurrent attention mechanism를 기반함
- simple-language QA, LM에서 좋은 성능을 거두었음
- Transformer
- input&output representation을 계산하기 위해 self-attention에만 의존
- sequence-aligned RNN or convolution사용하지 않음
Model Architecture
- encoder-decoder structure임
- encoder : $(x_1, … , x_n)$ → $(z_1, …, z_n)$
- $(z_1, …, z_n)$는 continuous representation
- decoder : $(z_1, … , z_n)$ → $(y_1, …, y_n)$
- 각 단계는 auto-repressive
- 즉, 이전에 생성된 symbol을, 다음을 생성할 때 additional input으로 넣음
- 각 단계는 auto-repressive
→ transformer는 encoder-decoder architecture에 stacked self-attention과 fully connected layer를 사용함
- encoder : $(x_1, … , x_n)$ → $(z_1, …, z_n)$
encoder는 input sequence의 representation(x1, .. ,xn)을 mapping 하고,
decoder는 주어진 z에 대해 (z는 (z1, .. ,zn )이고, 연속적임) output sequence (y1, .. ym)을 만들어낸다.
이때 매 단계마다 이전에 만들어진 symbol을 auto-regressive하게 추가 input으로 사용한다.
[위키백과, Auto-regression model]
The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation (or recurrence relation which should not be confused with differential equation).
Transformer model은 encoder와 decoder 모두에 대해 누적된 self-attension과 point-wise 방식의 fully-connected-layer를 사용한다.
encoder 에서는 N = 6인 layer를 사용하였는데, 각 layer는 2개의 sub-layer를 가지며
그 첫 layer는 multi-head self-attention mechanism, 두번째 layer는 position-wise fully connected feed-forward network이다.
이 두 개의 sub-layer에 residual connection을 이용하여 input을 output으로 그대로 전달해준다. 이후 layer normalization을 적용한다.
decoder에서도 N = 6인 layer를 갖지만, 각 layer는 3개의 sub-layer를 가진다.
마찬가지로 sub-layer에 residual connection한 후 layer normalization을 해주지만,
decoder에서는 순차적인 결과를 만들어내기 위해 masking한다.
masking이란, self-attention을 변형함으로서, 특정 지점에 대한 prediction을 해당 시점에서 이미 알고 있는 output들에만 의존을 하도록 하는 것이다.
Attention
Attention function은 query와 key-value들을 output에 mapping 해준다.
음 attention이라는 이름답게 특정 정보에 좀 더 주의를 기울이는(attention) 것입니다.
이 논문에서는 아래와 같은 Scaled Dot-Product Attention, Multi-head attention를 이용한다.
(수식이 너무 많아, 다른 블로그의 정리글들을 참고했다. )
Scaled Dot-Product Attention
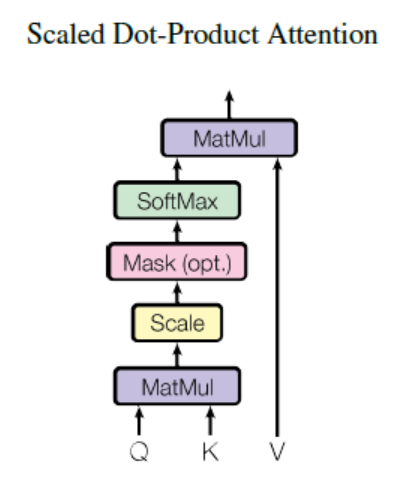
모든 query와 key에 대한 dot-product를 계산하고 각각을 √dk 로 나누어준다. (scaling)
이후 여기에 softmax를 적용해 value들에 대한 weights를 얻어낸다.
output은 각 value의 weighted sum이다.
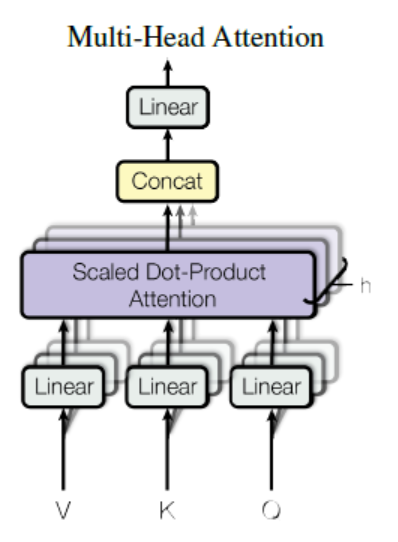
Multi-head attention

Why Self-Attention ?
-
Layer 당 총 계산 복합성 (간단함)
-
parallelize할 수 있는 계산의 양
-
network 내에서 long-range dependency간의 길이 (짧음)
Training
B1 = 0.9, B2 = 0.98이며, ε = 10^-9인 Adam optimizer를 이용하였으며
Residual Dropout 을 0.1로 이용하였고, 아래와 같은 성능을 도출했다.
```
Workflow
- Q, K, V 벡터 구하기
- Scaled Dot-Product Attention (행렬 연산으로 구현)
- 내부에 Padding Mask : Pad token을 연산에서 제외시킴
- Multi-head Attention …
Reference
-
https://medium.com/platfarm/%EC%96%B4%ED%85%90%EC%85%98-%EB%A9%94%EC%BB%A4%EB%8B%88%EC%A6%98%EA%B3%BC-transfomer-self-attention-842498fd3225
-
https://en.wikipedia.org/wiki/Autoregressive_model
-
https://pozalabs.github.io/transformer/