이번에 정리해볼 논문은,
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
나만 빼고 다 읽어본 거 같은, 나만 빼고 다 써본 적 있는 것 같은 BERT,, 조금씩 읽어나가면서 수정하고 추가할 예정 !
BERT는 Bidirectional Encoder Representation from Transformer의 약어로, 이름에서 모든 특징을 설명해주는 모델이다.
사실 BERT의 약어를 이루는 각각의 용어들이, 내게는 너무 모호하게 느껴지는
즉 대략적인 의미만 알지 구체적인 flow를 모르는 것들이라, 하나하나 공들여 읽어보기로 !!
아래와 같은 질문에 초점을 두고 읽었다.
1. transformer가 어떻게 이용되었는가? (다른 모델에서의 transformer와 다르게 사용되었는가?)
2. ELMO와의 차이는?
3. pre-training의 의미는?
4. 어떤 점 때문에 다양하게 활용 가능한가?
[Index]
우선 index를 살펴보면,
1. Introduction
2. Related Work
2.1 Unsupervised Feature-based Approachs
2.2 Unsupervised Fine-tuning Approach
2.3 Transfer Learning from supervised data
3. BERT
3.1 Pre-traning BERT
3.2 Fine-tuning BERT
4. Experiments
4.1 GLUE
4.2 SQuAD v1.1
4.3 SQuAD v2.0
4.4 SWAG
5. Ablation Studies
5.1 Effect of Pre-training Tasks
5.2 Effect of Model Size
5.3 Feature-based Approach with BERT
6. Conclusion
# Appendix
3. BERT에서 보이듯, BERT의 모델은 pre-training 부분과 fine-tuning 부분으로 나뉜다.
그리고 4. Experiment에서 fine-tuning의 차이를 두고 성능을 테스트한다
5. Ablation Study는 뭔지 몰라서 검색해봤는데, feature를 제거해가며 그것이 성능에 얼마나 영향을 끼치는지를 확인한다.
부록인 Appendix 에서는 Additional Details for Bert, Detailed Experimental Setup, Additional Ablation Studies를 다룬다.
[model architecture]
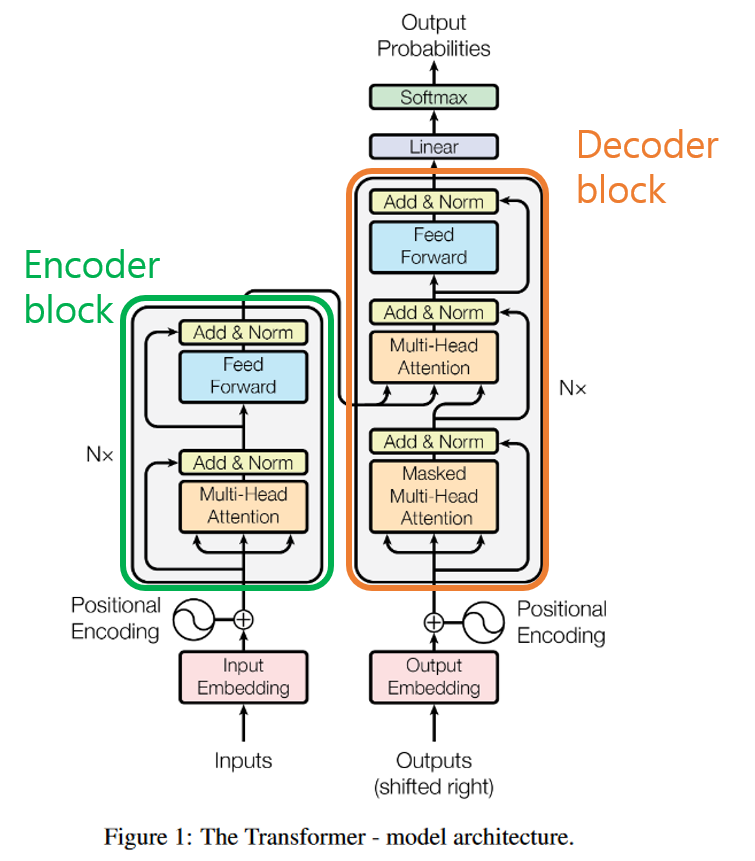
- Transformer - 설명 생략되어있음
- http://nlp.seas.harvard.edu/2018/04/03/attention.html :
Attention is all you need - bidirectional self-attention를 사용함
- flow는 따로 정리할 예정: 여기!
- http://nlp.seas.harvard.edu/2018/04/03/attention.html :
- 용어
- the number of layers as
L, the hidden size asH, the number of self-attention heads asA - input embedding as
E, the final hidden vector of the special [CLS] token asC ∈ R^H, the final hidden vector for the ith input token asTi ∈R^H.
- the number of layers as
- 크기에 따라 2가지 종류로 나뉨
BERT BASE(L=12, H=768, A=12, Total Parameters=110M)BERT LARGE(L=24, H=1024, A=16, Total Parameters=340M)
[input/output representation ]
- 문장의 시작은 [CLS]로 표시하고, 중간 띄어있는 공간은 [SEP]로 표시
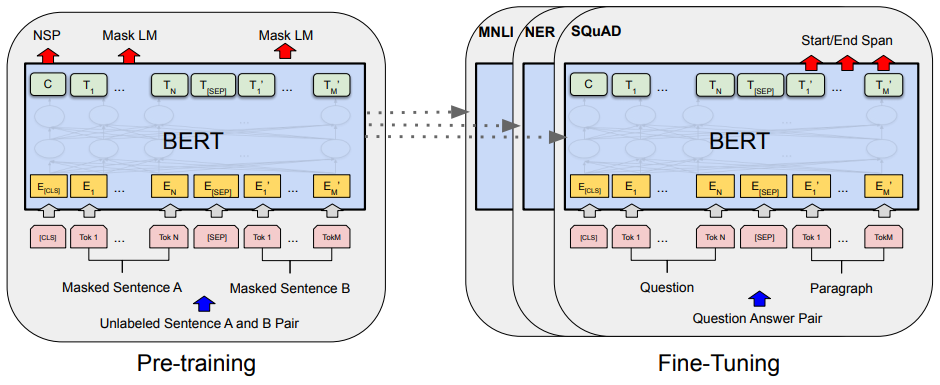
- input representation
- case 1)
single sentence- 바로 embedding 하여
sequence(BERT로의 input token sequence)로 만듦
- 바로 embedding 하여
- case 2)
a pair of sentences(e.g. <Question, Answer>)- case 1과의 구분을 위한 과정 거침
- 방법 1) 문장1 [SEP] 문장2
- 방법 2) 모든 token에 learned embedding을 추가하여 그것이 문장A에 속하는지 문장B에 속하는지 표시함
- 하나의 sequence로 함께 packing됨
sequence: BERT로의 input token sequence로서, 한개의 sentence or 함께 packing된 두개의 sentence
- case 1과의 구분을 위한 과정 거침
- case 1)
WordPiece Embedding이용- 아래 세가지 embedding을 결합하여 나타낸다.
- tokenizer를 통해서 입력 문장을 토큰단위로 쪼개고, 해당 토큰을 vocab에 매칭하여 id(숫자)로 입력한
token embedding - 각 토큰의 위치 정보를 임베딩하는
positional Embedding - 문장을 구분하는
segment embedding
- tokenizer를 통해서 입력 문장을 토큰단위로 쪼개고, 해당 토큰을 vocab에 매칭하여 id(숫자)로 입력한
- 아래 세가지 embedding을 결합하여 나타낸다.
[pre-training]
- unlabeled data에서 pre-training됨
- BooksCorpus (800M words) & English Wikipedia (2,500M words)를 사용했음 (
document-level corpus사용)
- BooksCorpus (800M words) & English Wikipedia (2,500M words)를 사용했음 (
-
training details
- batch size : 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch)
- 1,000,000 steps
Adamwith learning rate of 1e-4, β1 = 0.9, β2 = 0.999,L2weight decay of 0.01, learning rate warmup over the first 10,000 steps, and linear decay of the learning rate. We use a dropout prob- ability of 0.1 on all layers. We use agelu activation

-
two unsupervised tasks를 통해 pre-training되며, 두개의 loss를 합쳐 objective function으로 사용- Task #1: Masked LM (MLM)
- MLM이란? : 일정 비율의 input token을 masking하고, masked token을 predict함 (Cloze task)
- uniform masking rate of 15%
- 이 경우, mask token에 corresponding하는 final hidden vector는 vocabulary로 output softmax에 공급됨
- 이 논문에서, 전체 wordPiece token의 15%를 masking했으며, masked word만 predict 했음
-
deep bidirectional representation을 학습하기 위해, MLM으로 target token을 masking함
-
이때, 80%는 [MASK] token으로 masking하고, 10% 는 random word로 replace하고, 10%는 바꾸지 않음
-
80%: Apple is red and round -> Apple is [MASK] and round
-
15%: Apple is red and round -> Apple is sky and round
-
15%: Apple is red and round -> Apple is red and round
-
-
이를 통해 pre-training에서는 [MASK] token이 나타나지만, fine-tuning에서는 나타나지 않아 생기는 mismatch를 줄이고자 함
-
이때, random word로 replace하면 LM이 잘못된 언어능력(e.g. 문법 구사 능력 등)을 가지게 될 수 있는데, random replacement가 전체 token의 1.5% (i.e., 10% of 15%)이기 때문에, 모델의 language understanding 성능을 방해하지 않음
-
-MLM를 통해, Transformer encoder가 어떤 단어가 predict되는지, 어떤 단어가 random replace되는지 알 수 없음 → 따라서 모든 input token에 대해 distributional contextual representation를 유지하게 해줌
- MLM이란? : 일정 비율의 input token을 masking하고, masked token을 predict함 (Cloze task)
- Task #1: Masked LM (MLM)
2. Task #2: Next Sentence Prediction (NSP)
- 두 문장 사이의 관계 파악을 위한 task
- 문장 구성 ) A와 B(절반은 A뒤인 `IsNext`, 절반은 랜덤인 `NotNext`
- 각 문장에서 C는 NSP에 사용됨 (QA와 NLI에 좋음) but , NSP외에는 meaningless sentence
- cross entropy loss
### example of NSP
- Input
- [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
- Label ; `IsNext`
- Input
- [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- Label ; `NotNext`
[Fine-tuning]
Pre-train된 BERT모델을 이용해 수행하고자 하는 task를 추가 학습한다.
- For fine-tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters
- most model hyperparameters are the same as in pre-training,
- but,
Batch size: 16, 32,Learning rate (Adam): 5e-5, 3e-5, 2e-5,Number of epochs: 2, 3, 4 - dropout은 항상 0.1이고, optimal hyperparameter는 task-specific하다.
- BERT는 많은 downstream task(single text와 text pair 모두)를 수행할 수 있다 - by swapping out the appropriate inputs and outputs
Transformer덕분!- self-attention mechanism을 이용하여 concatenated text pair를 encoding 하는 것이 두 문장 사이의 bidirectional cross attention를 포함
- 이를 위해, task-specific 한 inputs & output을 BERT에 끼워넣고 end-to-end로 모든 parameter를 fine-tuning
- input에서는, pre-training된 문장 A,B가 아래 네가지와 유사함
- sentence pairs in paraphrasing
- hypothesis-premise pairs in entailment
- question-passage pairs in question answering
- a degenerate text-∅ pair in text classification or sequence tagging
- output에서는,
- token representation이 token-level task(e.g. sequence tagging, QA)를 위해 output layer에 들어감
- [CLS] representation이 classification(e.g. entailment,sentiment analysis) 을 위해 output layer에 들어감
- self-attention mechanism을 이용하여 concatenated text pair를 encoding 하는 것이 두 문장 사이의 bidirectional cross attention를 포함
- Compared to pre-training, fine-tuning is relatively inexpensive (typically very fast)
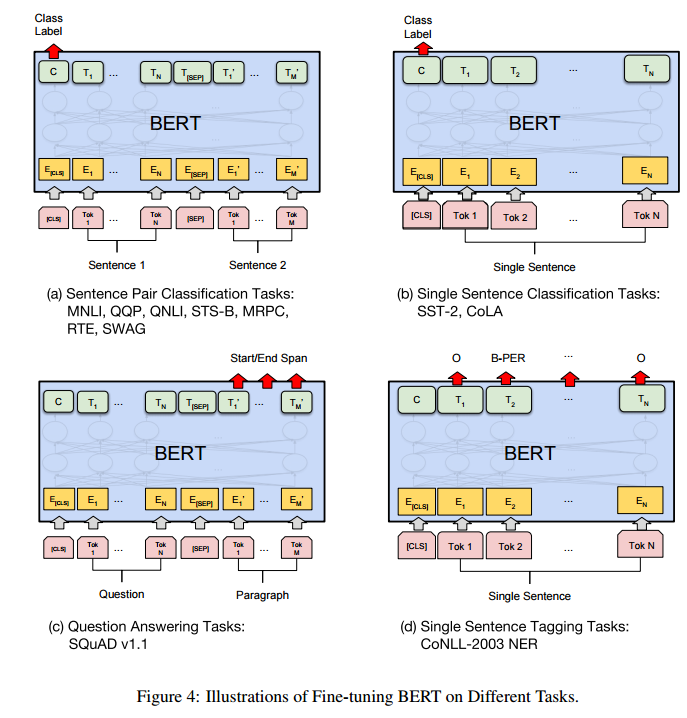
- 위 그림에서,
- (a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다.
- (b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다.
- (c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다.
- (d)는 입력 문장 Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging) 를 구하는 문제이다. 다른 Task들과 다르게 입력의 모든 Token들에 대해 결과를 구한다.
따라서 처음에 제시했던 아래 질문들에 대해서는 다음과 같이 답할 수 있겠다.
1. transformer가 어떻게 이용되었는가? (다른 모델에서의 transformer와 다르게 사용되었는가?)
- <Attention is all you need> 에서의 Transformer 중에서 Encoder부분 만 사용하여 Input을 Embedding한다.
2. ELMO와의 차이는?
- ELMO는 left-to-right & right-to-left LSTM을 따로 학습시킨 후 concatenation하여 downstream task의 feature(context-sensitive feature)를 만든다.
- 반면, BERT는 모든 Layer에 대해 left & right context를 jointly conditioned 한다.
- ELMO는 feature-based approach 이다.
- 반면, BERT는 fine-tuning approaches 이다.
3. pre-training의 의미는?
- Encoder가 입력 문장들을 임베딩 하여 언어를 모델링하는 언어 모델링 구조 과정
- pre-training을 마친 embedding 은 corpus의 의미적, 문법적 정보를 충분히 담고 있어, BERT의 등장 이후로 pre-trained model을 어떻게 사용하는지가 관건이 되었다.
4. 어떤 점 때문에 다양하게 활용 가능한가?
- task-specific 한 inputs & output을 BERT에 끼워넣고 end-to-end로 모든 parameter를 fine-tuning함.
- self-attention mechanism을 이용하여 concatenated text pair를 encoding 하는 것이 두 문장 사이의 bidirectional cross attention를 포함하기 때문 !
이해에 참고한 링크
- https://velog.io/@jinml/BERT
- https://reniew.github.io/47/
- https://towardsdatascience.com/bert-why-its-been-revolutionizing-nlp-5d1bcae76a13