지난번 소개했던 BERT에는 multi-lingual model이 존재하고 그 중 korean 도 있지만,
여러가지 한계가 존재하였고, 이를 보완하기 위해 다양한 Korean pre-training model이 존재해왔다.
이번 포스팅에서는 KoBERT, KorBERT, HanBERT, KoELECTRA 를 소개하고자 한다.
0. multilingual-BERT
multilingual-BERT는 104 languages에 대해,
12-layer, 768-hidden, 12-heads, 110M parameters를 활용하였으며, 이 중 korean도 포함된다.
1. koBERT
우선 koBERT는 multilingual-BERT의 한계를 극복하기 위해 만들어졌다.
korean wiki 5M sentence를 sentencePiece tokenizer를 이용하여 아래와 같이 tokenize했다.
한국어 모델을 공유합니다. → ['▁한국', '어', '▁모델', '을', '▁공유', '합니다', '.']
model size는 351M, vocab size는 8002이며
아래와 같이 다운로드하여 사용할 수 있다
git clone https://github.com/SKTBrain/KoBERT.git
cd KoBERT
pip install -r requirements.txt
pip install .
2. KorBERT
KorBERT는 ETRI에서 발표한 모델이다.
기존 KoBERT보다 많은 양의 데이터(신문기사와 백과사전 등 23GB의 대용량 텍스트를 대상으로 47억개의 형태소)를 사용하여 학습하였으며,
한국어의 특성을 반영한 “형태소분석 기반의 언어모델”과 형태소분석을 수행하지 않은 “어절 기반의 언어모델” 을 공개했다.
vocab size는 30797이다. vocab size역시 KoBERT보다 훨씬 크다.
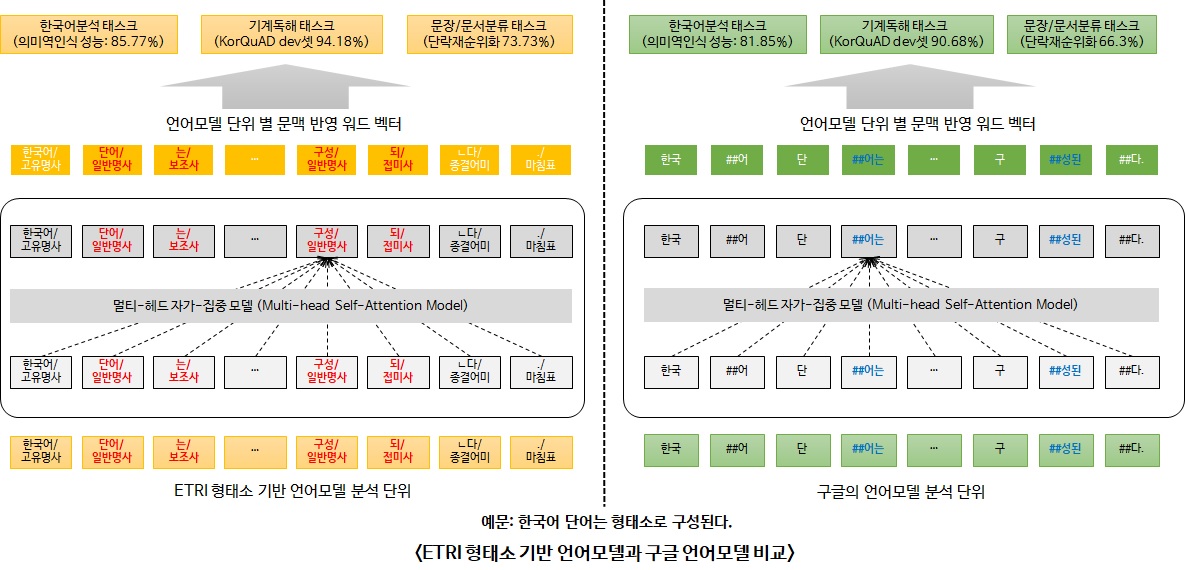
위는 BERT와 KorBERT를 비교한 그림이며, KorBERT는 사용허가협약서 작성 후 신청해야 사용할 수 있다.
3. HanBERT
일반문서 350M 특허문서 370M sentence를 사용하여 학습하였으며,
자체적으로 만든 tokenizer를 이용해 아래와 같이 tokenization했다.
나는 걸어가고 있는 중입니다.
나는걸어 가고있는 중입니다.
잘 분류되기도 한다.
잘 먹기도 한다.
→
['나', '~~는', '걸어가', '~~고', '있', '~~는', '중', '~~입', '~~니다', '.',
'나', '##는걸', '##어', '가', '~~고', '~있', '~~는', '중', '~~입', '~~니다', '.',
'잘', '분류', '~~되', '~~기', '~~도', '한', '~~다', '.',
'잘', '먹', '~~기', '~~도', '한', '~~다', '.']`
vocab은 총 54000표제어(53800개 단어 + 200개의 여유 공간)를 가지며, model size는 614M로 KoBERT보다 크다.
HanBert-54kN, HanBert-54kN-IP, HanBert-54kN_MRC 등을 함께 배포하고 있다.
4. KoELECTRA
KoELECTA는 34GB의 한국어 text로 학습되었으며,
ELECTRA를 적용하여 만들어졌다.
Vocab size (8002개)가 상대적으로 작은 KoBERT 와, Tokenizer로 인해 Ubuntu 환경에서만 사용 가능한 HanBERT와,
API 신청 등의 과정 필요한 KorBERT 의 단점을 보완하기 위해 만들어졌으며

vocab size은 32200이고,
각각 v1, v2, v3에 base, small model이 존재하는데, small model은 size가 412M 이다.
v1은 korean wiki, 나무위키, 뉴스(2.6B) 텍스트를 바탕으로 제작하였으며
v2는 EnlipleAI PLM에서 사용된 vocabulary를 이용하여 제작하였고,
v3은 모두의 말뭉치를 추가적으로 사용하고, Vocab도 Mecab과 Wordpiece를 이용하여 새로 만들었다.
electraTokenizer를 이용하여 아래와 같이 진행하였다.
[CLS] 한국어 ELECTRA를 공유합니다. [SEP]
→
['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]']
이 밖에도, Korea New Comment dataset을 이용한 KC-BERT, KC-ELECTRA 나
enlipleAI에서 발표한 PLM 도 있지만 이 부분은 추후에 포스팅할 예정이다 ☺️
Reference
-
https://github.com/SKTBrain/KoBERT
-
https://aiopen.etri.re.kr/service_dataset.php
-
https://github.com/monologg/HanBert-Transformers
-
https://twoblockai.com/2020/01/22/hanbert%EB%A5%BC-%EA%B3%B5%EA%B0%9C%ED%95%A9%EB%8B%88%EB%8B%A4/
-
https://github.com/monologg/KoELECTRA
-
https://monologg.kr/2020/05/02/koelectra-part1/
-
https://monologg.kr/2020/05/02/koelectra-part2/