이번에 소개할 model은 2020년 google이 발표한 ELECTRA이다.
ELECTRA는 Baseline인 BERT를 어떻게 하면 ‘가볍게, 그러나 성능은 그대로’ 할 수 있을지에 초점을 두었다.
1. Introduction
-
BERT와 같은 Masked Language Model (MLM) pre-training method는 성능은 좋지만 compute가 많이 필요하다.
-
본 논문에서는 보다 sample-efficient한 pre-training task인
replaced token detection을 제시한다.- small generator network로부터 나오는 alternative sample들로 몇가지 token을 replace한 후(
Generator), 각 token이 replaced token인지 여부를 predict(Discriminator) 하도록 한다.
- small generator network로부터 나오는 alternative sample들로 몇가지 token을 replace한 후(
-
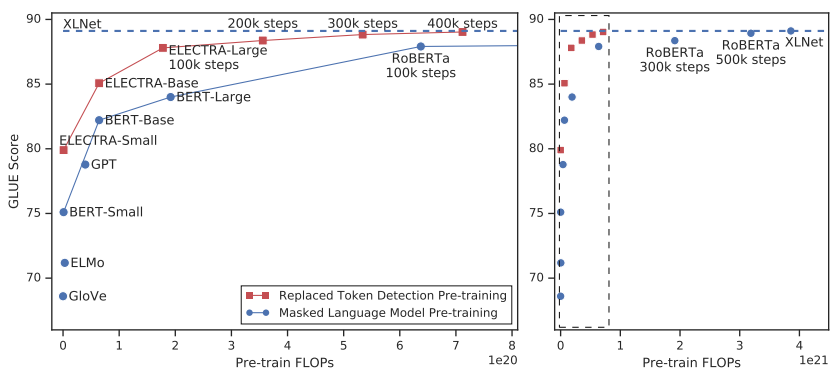
확실히 ELECTRA는 적은 FLOPs(Floating Point Operations)로도 성능이 좋다
- 기존 bert가 15%만 masking 한것에 비해, ELECTRA는 all input token으로부터 학습을 하기 때문에 much faster & more efficient
2. Method
-
generator와 discriminator는 Transformer network등등의 encoder로 이루어져 있다.
- encoder는 input tokens x = [x1, .. , xn]에 대해, contextualized vector representation인 h(x) = [h1, … , hn]으로 mapping한다.
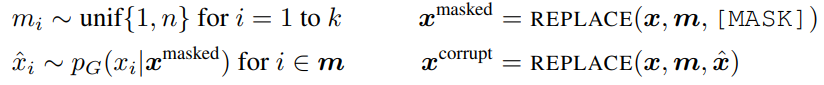
-
Generator ; MLM을 수행하도록 training 된다
-
PG(xt|x)는 position t에서, particular token xt을 만들어낼 확률 (xt= [MASK]) -
먼저 주어진 x = [x1, … , xn]에 대해 m = [m1, … mk]로 mask out하는 position의 random set을 select한다
- select된 position들은 [MASK] token으로 대체됨 (일반적으로 15%) (
x_masked)
- select된 position들은 [MASK] token으로 대체됨 (일반적으로 15%) (
-
이후 generator가 masked-out token의 original identity를 predict하도록 학습한다.
-
-
Discriminator ; token xt가 진짜인지를 predict한다.
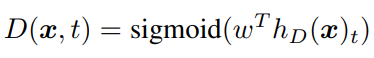
-
masked-out token을 generator sample로 replace하여 corrupted example을 형성한다 (
x_corrupt) -
이후 discriminator가
x_corrupt의 어떤 token이 original input x와 match되는지 predict하도록 학습한다
-
ELECTRA는
Generator&Discriminator로 이루어져 있지만GAN과는 매우 다르다.-
text를
GAN에 적용하기 힘드므로, maximum likelihood로 generator를 학습시킴 (즉, discriminator를 속이기 위한 학습이 아님) -
GAN과 달리 generator에서 noised vector를 input으로 주지 않음
-
generator에서, random set의 random sampling 결과에 대한 backpropagation이 힘듦
-
-
즉, model input은
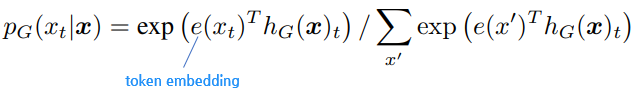
- loss function은
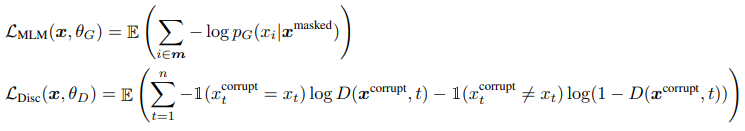
3. Experiments
3.1 Experimental setup
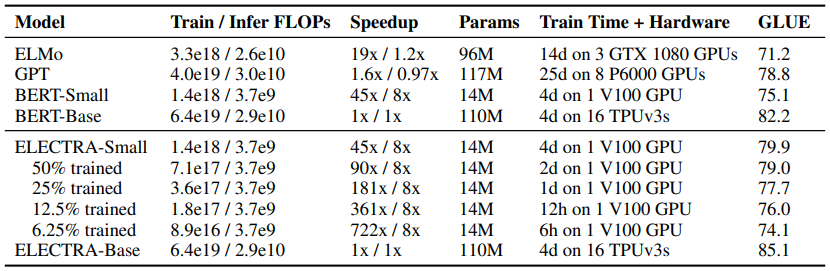
- GLUE task, SQuAD 수행하여 비교
3.2 model extensions
-
보다 효율적인 학습을 위해 아래 세가지 적용
-
weight sharing
(1) 임베딩의 가중치만 공유하고 그 외의 가중치는 따로 학습시키거나 (2) 모든 가중치를 서로 공유하는 방법
→ 모든 가중치를 공유하는 것이 가장 좋은 성능
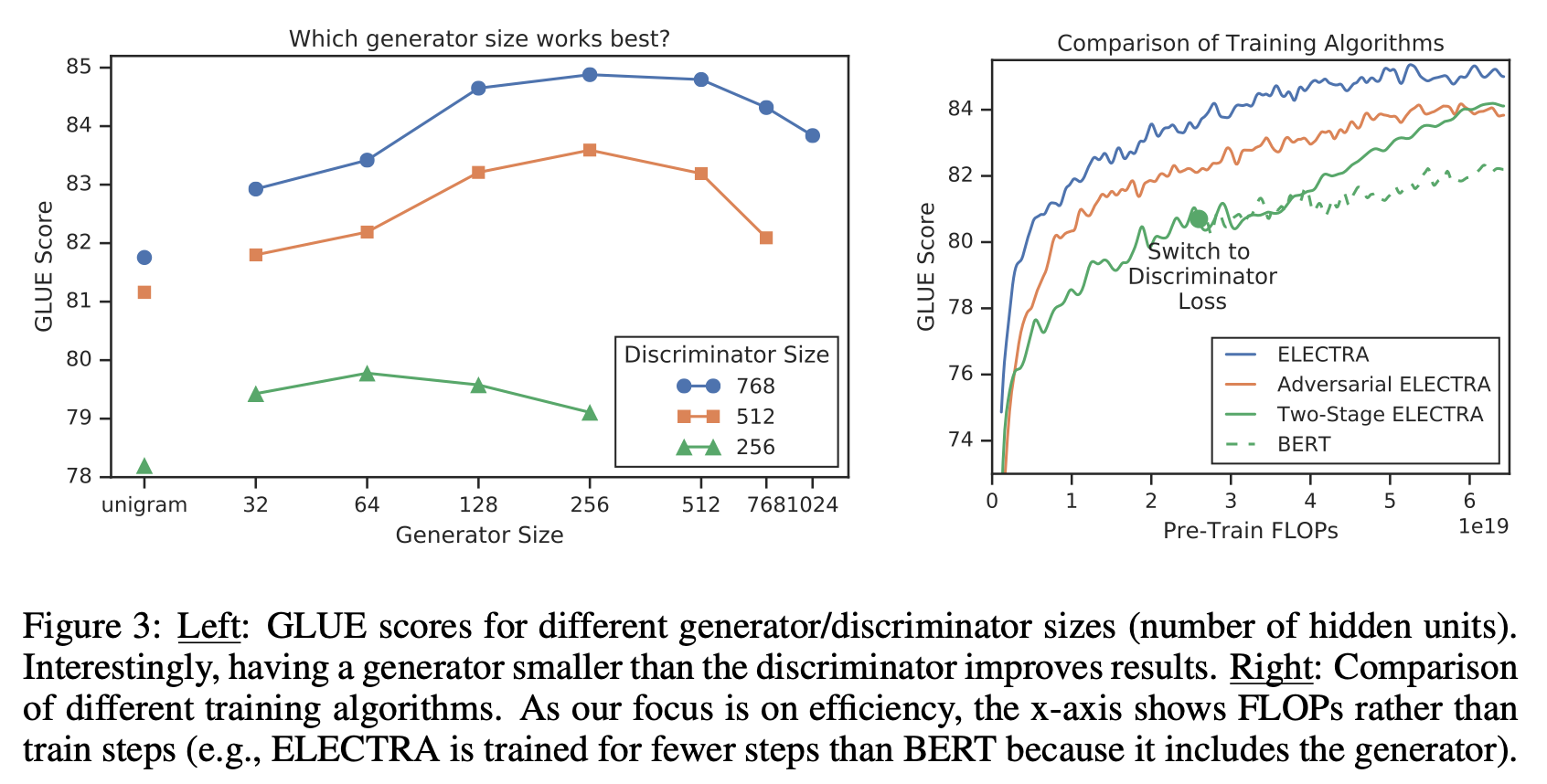
- smaller generator
-
Generator와 discriminator의 크기를 동일하게 가져간다면, ELECTRA를 학습하기 위해서는 BERT와 같은 일반 MLM 모델에 비해 단순 계산으로 거의 두 배의 계산량이 필요
→ 이를 위해 generator의 크기 줄이는 실험
-
discriminator의 크기 대비 1/4 - 1/2 크기의 generator를 사용했을 때 가장 좋은 성능
→ Generator가 너무 강력하면 discriminator의 태스크가 너무 어려워져서 이런 현상이 나타날 수 있다. 게다가 discriminator의 파라미터를 실제 데이터 분포가 아닌 generator를 모델링하는 데 사용할 수도 있다.
-
- training algorithm
-
training objective는 generator와 discriminator를 jointly 학습하는 것
→ 2가지 stage로 진행
- Two-stage 학습 : 1) generator만 LMLM 으로 n 스텝 동안 학습시키고, 2) discriminator를 generator의 학습된 가중치로 초기화하고 LDisc로 discriminator만 n 스텝 동안 학습시키는 방식 (이때 generator의 가중치는 고정)
- Adversarial 학습 : GAN처럼 adversarial training을 모사해서 학습시키는 방식
→ generator와 discriminator를 jointly 학습시키는 방식이 가장 좋음
-
3.3 small models

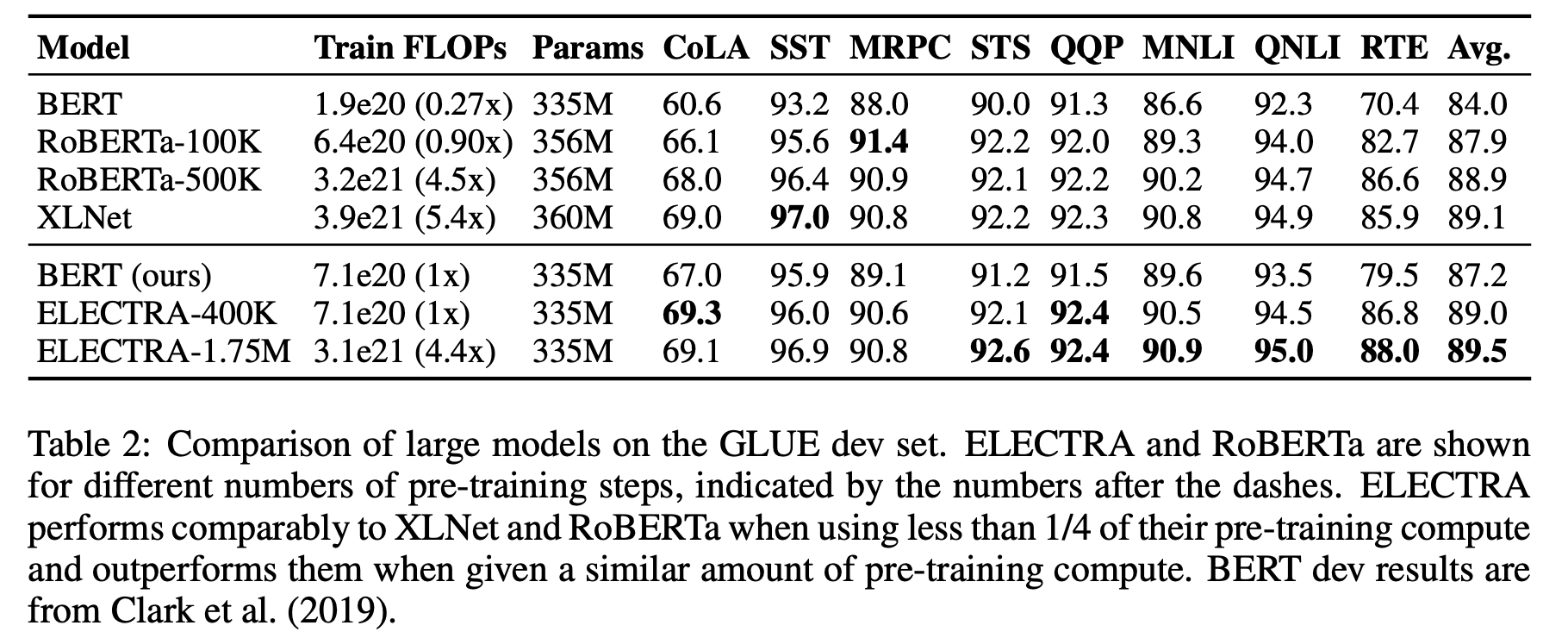
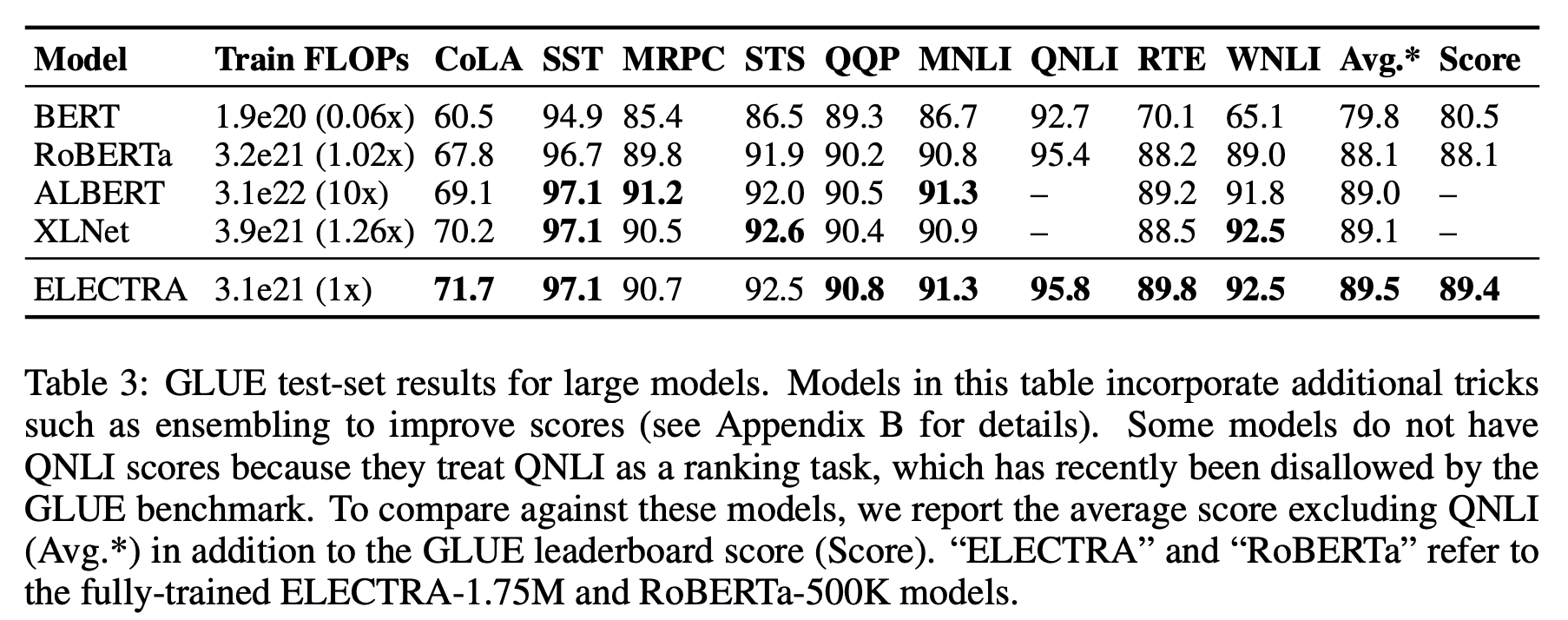
→ ELECTRA-400K는 RoBERTa(-500K)나 XLNet의 단 1/4의 계산량(FLOPs)만으로 이들과 필적할 만한 성능을 보임
- 더 많이 학습시킨 ELECTRA-1.75M은 이들을 뛰어넘는 성능을 보였고, 이 역시도 계산량은 두 모델보다 작음
- GLUE뿐만 아니라, SQuAD에서도 마찬가지로 ELECTRA는 가장 좋은 성능을 보임
3.4. large models
3.5 Efficiency Analysis
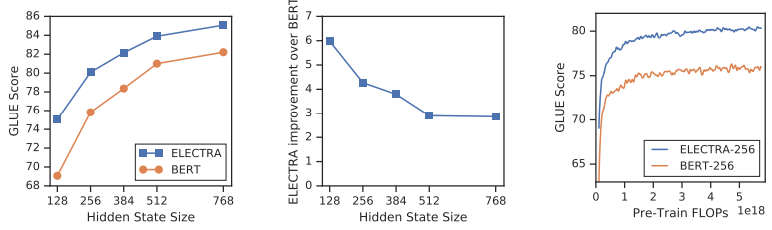
- all token에 대해 loss를 계산하는 것이 효과적이다.
4. Related Work
Self-supervised Pre-training for NLP
- BERT, XLNET, tinyBERT, …
Generative Adversarial Networks
- GAN, MaskGAN, …
Contrastive Learning
- NCE(Noise-Contrastive Estimation), Word2Vec, CBOW, …
5. Conclusion
-
본 논문은 language representation learning에 새로운 self-supervised task 를 제시했음
-
key idea는, generator network로부터 생성되는 token이 negative sample인지 input token인지를 학습시키는 것이다.
-
more compute-efficient, better performance
Reference
- https://littlefoxdiary.tistory.com/41