이번에 읽을 논문은 permutation language model이라고도 불리는 XLNET이다.
2019년에 나타나서, 대부분의 nlp task에서 BERT를 꺾고 SOTA로 등극한 논문이다!! (현재까지도 text classification에서의 SOTA인 듯 하다)
1. Introduction
- 최근 NLP에서, unlabeled large-scale corpus로 pre-training 후 downstream task로 fine-tune하는 것이 대세인데, 크게
AR과AE로 나뉨-
AR(AutoRegressive) Language Model-
autoregressive model로, text corpus의 확률분포를 추정한다.
- 즉, 이전 문맥을 바탕으로 다음 단어를 예측하는 과정에서 학습함
-
AR에서는 uni-directional context만 학습하지만, downstream에서는 bidirectional context information을 필요로 한다
-
따라서, AR language modeling이 effective pretraining이라고 말하기는 힘듦
-
ELMO는 pre-traning에서 forward, backward layer를 각각 독립적으로 학습하기 때문에 진정한 bidirectional model이라고 하기 힘듦
-
-
e.g. ELMO, GPT
-
-
AE(AutoEncoding) Language Model-
corrupted input으로부터 original data를 reconstruct한다.
-
e.g. BERT(Denoising Autoencoder)
-
그러나, BERT의 Pretraining과정에서 쓰이는
[token]은 fine-tuning에서의 real data에는 존재하지 않음 -
BERT는 unmasked tokens을 모두 independent하다고 가정 (즉, 두 단어의 선후 관계나 등장 여부 등을 고려하지 않음)
-
-
-
-
본 논문에서는, AR LM과 AE LM을 모두 살린
XLNET( generalized autoregressive method )을 제안함-
XLNET은 모든 가능한 factorization order에 대해 sequence의 expected log likelihood 를 구함
-
XLNET 은 data corruption에 의존하지 않아(input data에 noise를 추가하지 않아) BERT에서의 문제점(pre-train에 사용하는 data와 fine-tuning에 사용하는 데이터의 불일치)가 없음
-
XLNET은 autoregressive objective으로 예측된 token의 jointly probability를 구하는 product rule을 제공하므로, BERT에서의 independence assumption이 없음
-
Transformer-XL의 segment recurrence mechanism과 relative encoding scheme를 pre-training에 통합함으로서 긴 sequence에서의 성능 향상을 꾀함
-
2. Proposed Method
2.1 Background
- conventional AR language modeling과 BERT를 비교
| AR modeling | AE modeling (e.g. BERT) | |
|---|---|---|
| Independence Assumption | - independece assumption 없음 | |
| - 보편적인 product rule을 사용하여 p_θ(x)를 인수분해함 | all masked token x-가 seperately reconstructed한다는independece assumption을 기반으로, joint conditional probability p(x- | x~)를 인수분해함 |
| Input noise | does not rely on any input corruption | [MASK]와 같이, downstream task에서 벌대 없는 symbol이 input에 존재함 : pretrain-finetuning discrepancy |
| Context dependency | AR representation h_θ(x1:t−1)는, position t까지의 token만을 conditioning (즉, unidirectional) | BERT representation H_θ(x)t는 bidirectional context information에 access가능 (즉, diriectional context를 더 잘 capture함) |
2.2 Objective: Permutation Language Modeling

-
factorization order에 대해서만 Permutation하고 original sequence order는 남김
-
original sequence에 상응하는 positional embedding으로 token간의 위치정보 구분 가능
2.3 Architecture: Two-Stream Self-Attention for Target-Aware Representation

Two-stream self-attention
Partial Prediction
- permutation의 문제점인 느린 시간을 보완하기 위해, 마지막 몇개의 token만을 예측함
2.4 Incorporating ideas from Transformer-XL
이전 논문인 Transformer-X에서 다음과 같은 두가지를 착안함
-
Relative positional embedding
-
Segment recurrence mechanism
2.5 Modeling Multiple Segments
-
XLNET은 segment도 encoding함 ; 두 potision i,j가 같은 segment에 있는지를 확인하기 위해
-
pretraining 단계에서, 임의의 두 segment를 random하게 선택하여 하나의 sequence로 취급
2.6 Discussion
- GPT와 달리, 양방향 dependency를 잡아낼 수 있음!
3. Experiments
3.1 Pretraining and Implementation
3.2 Fair Comparison with BERT

3.3. Comparison with RoBERTa: Scaling UP

3.4 Ablation Study
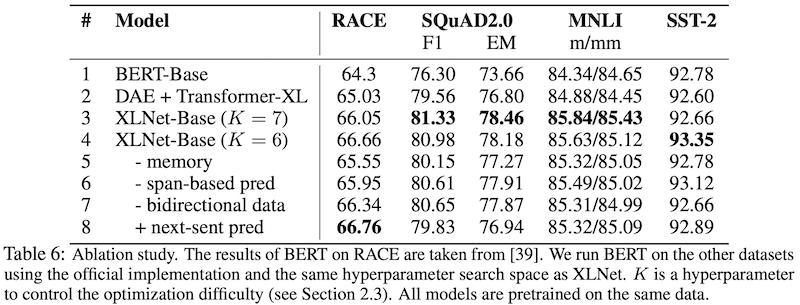
Transformer-XL과 permutation LM의 성능이 확연하게 뛰어남을 알 수 있다.
4. Conclusion
-
XLNet is a generalized AR pretraining method that uses a permutation language modeling objective to combine the advantages of AR and AE methods.
-
The neural architecture of XLNet is developed to work seamlessly with the AR objective, including integrating Transformer-XL and the careful design of the two-stream attention mechanism.
-
XLNet achieves substantial improvement over previous pretraining objectives on various tasks.
Reference
-
https://machinereads.com/2020/05/10/xlnet-generalized-autoregressive-pretraining-for-language-understanding-1-3/
-
https://ratsgo.github.io/natural%20language%20processing/2019/09/11/xlnet/
-
https://blog.pingpong.us/xlnet-review/
-
https://novdov.github.io/machnielearning/nlp/2019/07/13/XLNet-%EB%A6%AC%EB%B7%B0/
-
http://naveedshare-licensetoplay.blogspot.com/2019/08/xlnet-sota-model.html
-
https://www.google.com/url?sa=i&url=https%3A%2F%2Fcompstat-lmu.github.io%2Fseminar_nlp_ss20%2Ftransfer-learning-for-nlp-ii.html&psig=AOvVaw0I-_t4oB67-wCRizmiC4Zp&ust=1623074282821000&source=images&cd=vfe&ved=0CA0QjhxqFwoTCKDWjYaVg_ECFQAAAAAdAAAAABAD