XLNET을 읽다가, 도통 autoregressive model이 확 와닿지 않아서 먼저 GPT 읽기로 했다 !
{kind=link}
GPT는 “Transformer의 Decoder를 사용하여, Seq2Seq 학습 흐름에 내부 알고리즘은 Transformer에 Decoder를 사용해 학습이 진행”“되었다던데, 구체적인 flow가 궁금해서 논문을 읽어보기로 했다
논문 제목은 Improving Language Understanding by Generative Pre-Training이다.
1. Introduction
-
다양한 NLU task 중, large unlabeled text corpora는 많지만, specific task를 위한 labeled data는 적음 (so, 성능향상 어려움)
-
unlabeled text corpora에 대한 Language model을 generative pre-train 후 task-specific fine-tuning하면 성능 향상 가능
-
따라서, 본 논문에서
semi-supervised approach를 제안 (universal representation을 학습하기 위한 unsupervised pre-training + supervised fine-tuning)
-
-
아래와 같은 두가지 단계 존재
-
unlabeled data가 NN model에서 initial parameter를 학습하도록 language model objective를 사용
-
1에서의 parameter를, target task를 위한 supervised objective로 fine-tuning
-
-
Transformer, document generation, syntactic parsing을 사용
- Long-term dependency를 다루는 데 도움을 줌
2. Related Work
Semi-supervised learning for NLP
Unsupervised pre-training
Auxiliary training objectives
3. Framework
-
high-capacity language model을 학습 -> 특정 task에 대하여 라벨링된 데이터로 fine-tuning
-
forward 방향으로 학습 진행
3.1 Unsupervised pre-training
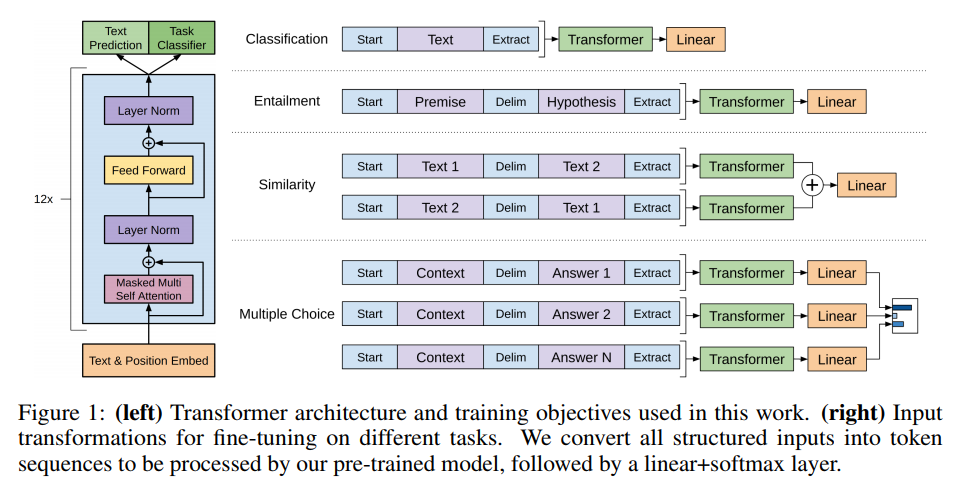
Transformer model의 decoder와 같은 구조임
3.2 Supervised fine-tuning
- LM objective에 대하여 모델을 pretraining한 후, labeld dataset 를 가지는 target task에 대해 parameter를 조정
3.3 Task-specific input transformations
- 각각 다른 fine-tuning task에 대해
4. Experiments
4.1 Setup
- BookCorpus dataset for pre-training
4.2 Supervised fine-tuning
5. Analysis
- Impact of number of layers transferred
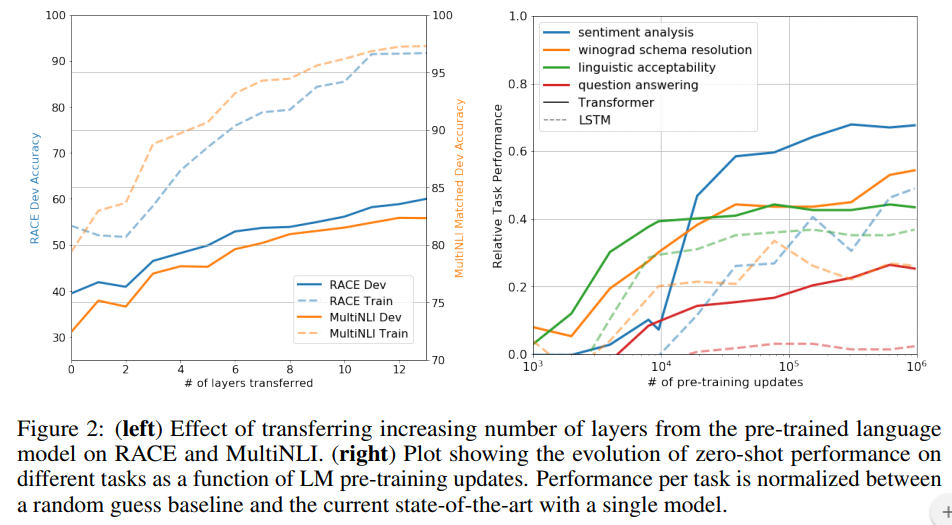
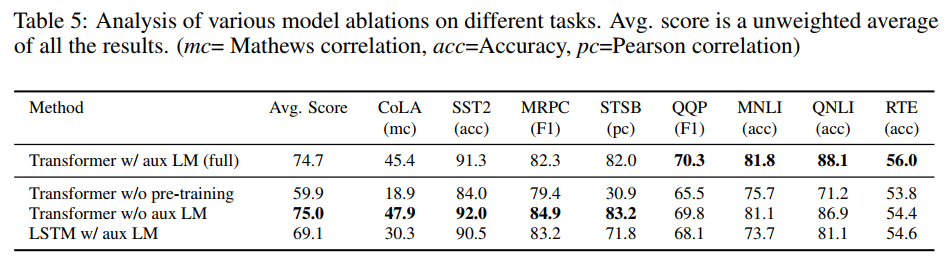
Ablation study
6. Conclusion
-
generative pre-training + discriminative fine-tunning 으로 NLU task의 성능 향상
-
길고 연속적인 text를 통해 학습함으로서 world knowledge, long-range dependencies 처리 가능
Reference
-
https://vanche.github.io/NLP_Pretrained_Model_GPT/
-
https://vhrehfdl.tistory.com/80
-
https://ratsgo.github.io/nlpbook/docs/language_model/bert_gpt/