Abstract
-
we collect and release a human-human dataset consisting of multiple chat sessions
-
We show how existing models trained on existing datasets perform poorly in this long-term conversation setting in both automatic and human evaluations,
-
we study long-context models that can perform much better.
-
we find retrieval-augmented methods and methods with an ability to summarize and recall previous conversations outperform the standard encoder-decoder architectures currently considered state of the art.
1. Introduction
we study methods for long-term open-domain conversation. As to the best of our knowledge no public domain task exists to study such methods
we collect and release a new English dataset, entitled Multi-Session Chat (MSC). The dataset consists of human-human crowdworker chats over 5 sessions
-
각 session은 최대 14개의 utterance로 이루어져 있음
-
이전 session에는 이후의 대화에 유용할 수 있는 personal point의 summarization이 annotate됨
→ 이를 fine-tuning에 적용함
We study the performance of two long-context conversational architectures on this task:
(i) retrieval-augmented generative models
(ii) a proposed read-write memory-based model that summarizes and stores conversation on the fly.
3. Multi-Session Chat
우리가 사용한 dataset은 MSC(multi-session chat)
-
” individual chat session is long” == 중간에 몇시간 ~ 며칠 paused 됨
- 우리는 이러한 multi-session long conversation setup을 고려함
-
Session 1에서는 기존 PERSONACHAT인 짧은 대화 내용을 바탕으로 처음 만난 두 사람의 간략한 정보만 서로 나누는 대화 태스크로 진행이 됩니다.
-
Session 2~4까지는 정해진 시간의 term(1~7시간 단위 또는1~7일 단위)을 두고, 기존 persona를 유지하고 이전에 했던 대화를 반영한 대화를 나누게 합니다. 마치 이전에 대화하다가 시간이 흘러 다시 대화를 나누는 두 사람처럼 주제가 확대될 때도 이전에 나눈 대화와 일관성이 있게 대화를 진행하게 합니다.
-
Conversation summaries (확장된 persona) 워커간에 이전 대화를 볼 수도 있고, 이전 히스토리의 파악이 가능한 환경을 주더라도 사람은 제한된 시간내에 그 정보를 읽고 활용하기는 한계가 있기 마련입니다. 따라서 각 session에서 중요 포인트를 기록하고 요약하여 대화의 참고 자료로 활용하게 합니다.
-
Dataset statics를 보면 이전에 구축한 짧은 2.6 ~ 14.77의 짧은 턴에 비해 MSC는 53 ~ 66턴 등의 긴 발화수를 가집니다.
몇시간 ~ 며칠 pause된 후 재개할때, 화자는 (i) 이전 주제에 대해 계속 이야기하거나 (ii) 과거 공유 기록에서 다른 주제를 꺼내거나 (iii) 새로운 대화를 다시 시작함
-
CrowdWorkers + 1155명의 Personas 사용; 첫번째 대화 이후 시간이 흐른 뒤 대화 하도록 .. or 그런 척
- 4000 episodes with 3 sessions, and 1001 episodes with 4 sessions.
4. # 4. Modeling Multi-Session Chat
- We consider using the BST 2.7B parameter model from Blender-Bot as an initial pre-trained model, which we then fine-tune on the Multi-Session Chat task.
- Encoder Truncation
- 기존에 encoding에서 128 token이었던 BST 2.7B보다 더 큰 input을 받도록 ; 256, 512 or 1024 tokens
4.2. Retrieval-Augmentation
-
a retrieval system is used to find and select part of the context to be included in the final encoding which is attended to by the decoder.
** FiD, RAG 설명; https://ratsgo.github.io/insight-notes/docs/qa/answerer#retrieval-augmented-generation
검색 시스템(retrieval system)은 디코더에 의해 제공되는 최종 인코딩에 포함될 컨텍스트의 일부를 찾아 선택하는데 사용
-
RAG(Retrieval-Augmented Generation)
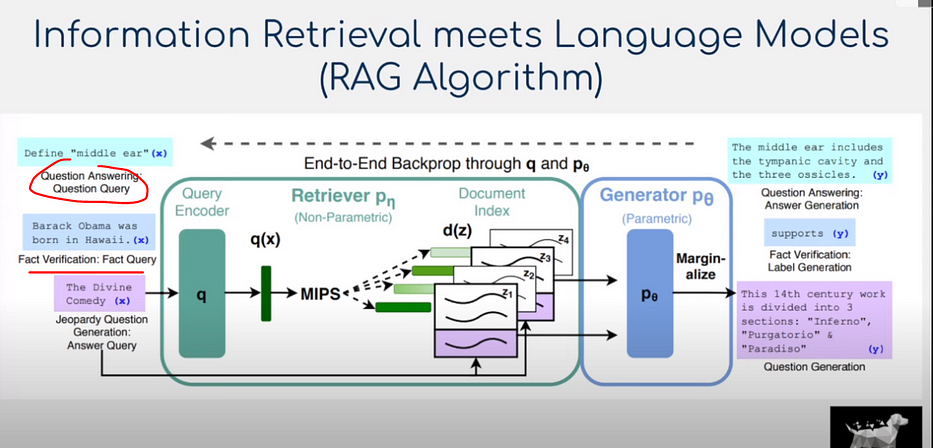
- RAG utilizes Neural-retriever-in-loop which is itself a Transformer
- 검색할 문서는 가장 가까운 FAISS index에 저장
- Dense Passage Retrieval(DPR) model이 FAISS index에서 검색 → 상위 N개 후보에 점수 매김 (document-context pair 이용)
- Transformer bi-encoder model을 사용하여 점수 매김
- end-to-end train
-
FiD(Fusion in Decoder)

- FiD의 답변 생성 방식; 쿼리와의 관련성이 높은 순서대로 N개 입력을 만들고 각각 인코더에 태워서 벡터로 인코딩합니다. 이 𝑁 개의 인코딩 벡터들을 합쳐(concatenate) 디코더에 넣고 답변을 생성
- FiD-RAG
- pre-trained retriever (RAG-trained retriever)
-
FiD를 고려한 방법임; return된 상위 N개의 문서 각각은 컨텍스트 앞에 추가되고 인코더에 의해 별도로 인코딩되며, 마지막으로 모든 결과가 concat됨.
그런 다음 디코더는 이러한 인코딩에 주의하여 최종 응답을 생성
- Retriever and Documents
-
memory의 모든 항목을 DPR model로 encoding하는 Vector에 저장 (FAISS 에서는 dense vector 사용)
→ dialog context가 주어지면 bi-encoder를 사용하여 각 memory에 점수 매김 & generation을 위해 상위 N개 사용
- 본 연구에서 memory는 대화 History에서 나온 dialog utterence
→ chunk(passage) 크기를 hyperparameter로 하여, utterance를 separate document로 encoding하거나, 전체 session 및 session summary를 separate document로 encoding
-
→ 단점 !!
-
The retrieval-augmentation model retrieves from the set of past dialogues. Simply storing historical context in the memory in its raw form is a simple approach that is often used elsewhere in the literature, e.g. in question answering or knowledge-grounded dia- logue. However, those approaches have two potential drawbacks:
(i) there is a lot of context to store, and hence retrieve from;
(ii) no processing has been done on that content, so the reading, retrieving and combining to finally generate leaves a lot of work for the model to do.
4.3. Memory Augmentation’s Summary
- retrieval-augmentation model의 단점을 보완하기 위해, We propose instead a memory augmentation that first summarizes the pertinent knowledge and only stores that instead in an attempt to solve both problems. (마지막 대화 차례에 포함된 새로운 관련 정보를 요약)
- The procedure involves two main components:
- An
encoder-decoder abstractive summarizerthat takes as input the dialogue history with the goal of summarizing any new pertinent information contained in the last dialogue turn. This includes the case of deciding that no new information should be stored in the memory. When found, the summarized knowledge is added to the long-term memory.- we can use the human annotated data from our newly collected MSC task to know what summaries to generate. We thus train a supervised encoder-decoder model to produce summaries.
즉, 마지막 대화에 포함된 새로운 정보가 있으면 장기기억 장치에 추가하는 기능;
SumMem model - A
memory-augmented generatorthat takes the dialogue context and access to the long-term memory, and then generates the next response. (대화 컨텍스트와 장기 기억에 대한 액세스를 가져오고 다음 응답을 생성)- we can use the same systems as presented in subsection 4.2 to both retrieve from the summarization memories, and to finally generate an appropriate response.
즉, 대화 컨텍스트와 장기 메모리에 접근하여 다음 답변을 생성하는데 사용
- An