- Attention mechanism은 NLP model에서 널리 사용되었음
- predictive performance 향상에 기여 & transparency 제공
- 그러나, attention weight와 model output이 어떤 relationship인지에 대한 내용이 제공되지 않음
-
본 논문에서는, 다양한 NLP task에서의 extensive experiment를 진행함
→ 대부분 prediction에 대해 meaningful “explanation”을 제공하지 않음을 확인함
- e.g. 대부분의 learned attention weight는 feature importance의 gradient-based measure과 correlation이 없으며, 그럼에도 동일한 predict를 산출하지만 다른 attention distribution을 identify함
→ 즉, 일반적인 attention module은 meaningfule explanation을 제공하지 않음 !!
1. Introducion and motivation
- Attention mechanisms이란?
- input unit에 대한 conditional distribution을 유도하여, downstream module에 대한 weighted context vector를 구성함
- attention을 통해 model의 inner-working에 대한 insight를 제공받기도 함 : 즉, neural model이 어떻게 작동하는지에 대한 설명으로 여겨졌음
- attention은 이제 NLP에서 near-ubiquitous module임
→ attention에 대한 이런 믿음은, high attention weight을 가지는 input은 model output에 responsible하다는 것을 전제로 함
→ 그러나 이는 검증되지 않았음 ,,,
→ 만약 이 전제가 사실이라면, 다음과 같은 property가 유지되어야 함
(i) Attention weights should correlate with feature importance measures (e.g., gradient-based measures)
(ii) Alternative (or counterfactual) attention weight configurations ought to yield corresponding changes in prediction (and if they do not then are equally plausible as explanations).
→ 본 논문에서는, standard attention mechanism + BiLSTM으로 QA, NLI task를 실험해봄
→ 실험 결과, (i), (ii)모두 consistent하지 않음,,,
- example in Figure 1
- 다른 단어에 대해 attention이지만, 예측 결과는 동일함
- 다음과 같은 empiricaal question을 탐색함으로서, 다른 task에서도 그런지 확인함
-
To what extent do induced attention weights correlate with measures of feature importance – specifically, those resulting from gradients and
leave-one-out (LOO)methods?→ Only weakly and inconsistently
-
Would alternative attention weights (and hence distinct heatmaps/“explanations”) necessarily yield different predictions?
→ No;
→ 즉,
- 완전 다른 input feature에 attention 을 적용했음에도, 원래 유도된 attention weight을 사용했을떄와 동일한 adversarial attention distribution을 생성함
- randomly permuting attention weight여도 output은 거의 같음(변화 거의 없음)
- 단순한 feedforward(weighted average) encoder의 attention weight은 더 나음 → 뭔소리여
-
2. Preliminaries and Assumptions
3. Datasets and Tasks
- binary text classification
- Stanford Sentiment Treebank (SST), IMDB Large Movie Reviews Corpus, Twitter Adverse Drug Reaction dataset, 20 Newsgroups, AG News Corpus (Business vs World), MIMIC ICD9 (Diabetes), MIMIC ICD9
- QA
- CNN News Articles, bAbI
- NLI
- SNLI dataset(with the labels neutral, contradiction, and entailment)
4. Experiments
- key questions
- Do learned attention weights agree with alternative, natural measures of feature importance?
- Had we attended to different features, would the prediction have been different?
4.1 Correlation Between Attention and Feature Importance Measures
- 사용 metrics
-
Total Variation Distance (TVD) to measure change between output distribution
-
Jensen-Shannon Divergence (JSD) to quantify the difference between two attention distributions
-
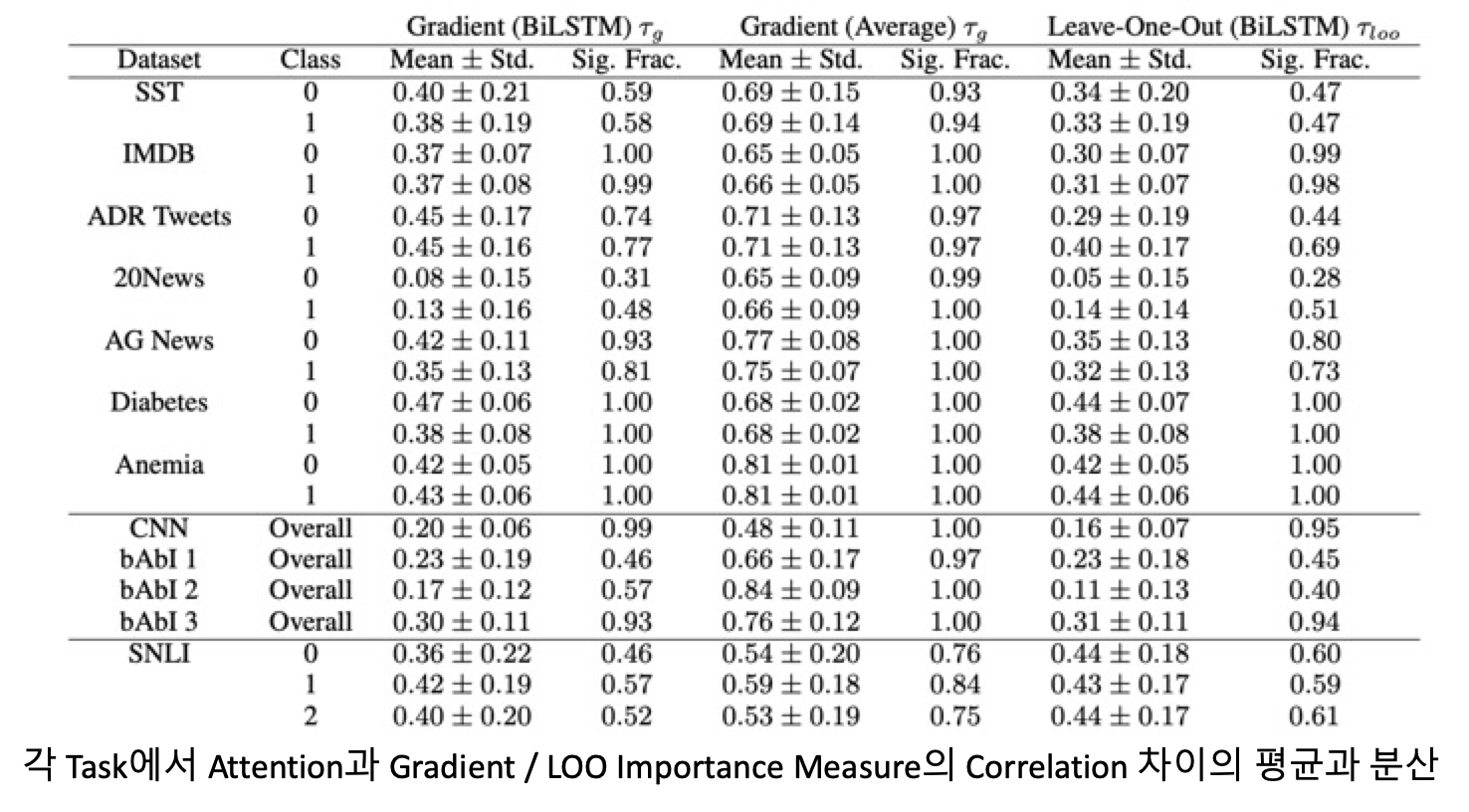
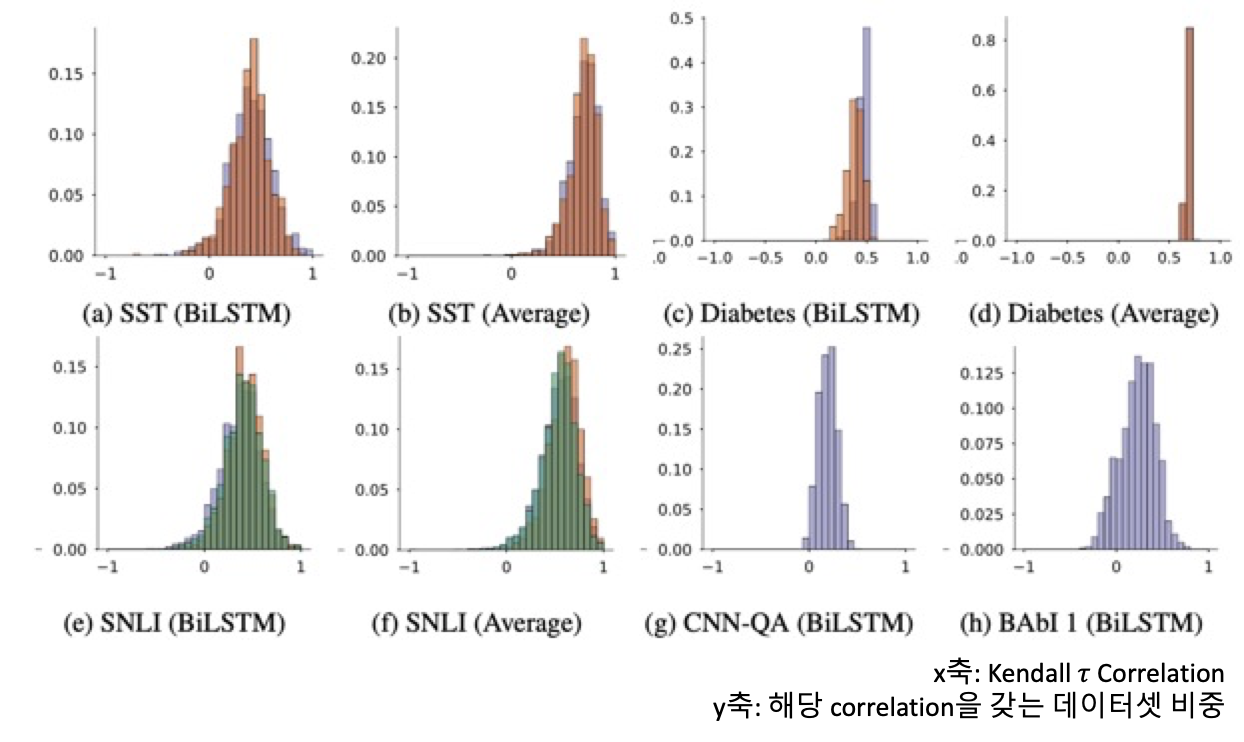
즉, (1) attention과 gradient based measures of feature importance ( $τ_g$)과의 correlation,
(2) attention과 differences in model output induced by leaving features out($(τ_loo)$ 와의 correlation
을 계산함으로서, semantic으로 individual feature importance를 측정함

→ result
A. Model details (Appendix)
- BiLSTM, CNN, Average
4.2. Counterfactual Attention Weights
→ model이 다른 input feature에 attention했을때 결과가 달라질까?
4.2.1 Attention Permutation
→ we first consider randomly permuting observed attention weights and recording associated changes in model outputs !


4.2.2 Adversarial Attention
→ We propose explicitly searching for “adversarial” attention weights that maximally differ from the observed attention weights (which one might show in a heatmap and use to explain a model prediction), and yet yield an effectively equivalent prediction !


5. Related Work [생략]
6. Discussion and Conclusions
- 결과
- 4.1에서는, intuitive feature importance measure(e.g. gradient, feature erasure approaches)와 learned attention weight 의 correlation이 약함을 밝힘
- 4.2에서는 model의 prediction 근거에 반하는 counterfactual attention distribution이 model output에 영향을 끼침을 밝힘
→ 즉, attention module은 NLP task에서의 성능 향상을 요하는건 맞지만, model prediction에 대한 meaningful explanation을 제공하는 것은 아님
- 특히 complex encoder가 사용되어, hidden state의 input이 얽힐 수 있음 (encoder에서 각 input의 임의의 interaction을 encoding하는 representation을 뱉어내기 때문)
- 또한 model이 도달한 특정 disposition과 attention weight은 항상 명확한 관계를 가지지 x
- limitation
- We do not intend to imply that such alternative measures(e.g. gradient) are necessarily ideal or that they should be considered ‘ground truth’.
- 모델이 특정 방식으로 입력을 처리했기 때문에 모델이 특정 예측을 했다고 결론지을 수는 없음
- we have only considered a handful of attention variants, selected to reflect common module architectures for the respective tasks included in our analysis.
- irrelevant features may be contributing noise to the Kendall τ measure, thus depressing this metric artificially.
- we have limited our evaluation to tasks with unstructured output spaces, i.e., we have not considered seq2seq tasks