1. INTRODUCTION
- Is having better NLP models as easy as having larger models?
- large-size의 pretraining model은 성능 향상을 가져왔지만, GPU/TPU memory limitation을 유발함
- 이를 해결하기 위해,
ALBERT제안- 2 parameter reduction techniques
-
factorized embedding parameterization
By decomposing the large vocabulary embedding matrix into two small matrices, we separate the size of the hidden layers from the size of vocabulary embedding. This separation makes it easier to grow the hidden size without significantly increasing the parameter size of the vocabulary embeddings.
-
cross-lingual parameter sharing
This technique prevents the parameter from growing with the depth of the network
-
→ 이전 BERT보다 훨씬 작은 크기, 빠른 학습 속도
- Sentence-order prediction(SOP)를 위한 self-supervised loss를 제안
- 2 parameter reduction techniques
- 다양한 task에서 SOTA달성
2. RELATED WORK
- SCALING UP REPRESENTATION LEARNING FOR NATURAL LANGUAGE
- CROSS-LAYER PARAMETER SHARING
3. The elements of ALBERT
BERT(transformer encoder)를 기본으로 함
3.1. model architecture choice
- Factorized embedding parameterization
- wordpiece embedding사용함
- modeling 관점에서 Wordpiece embedding은 context-independent representation을 배우고 hidden-layer embedding은 context-dependent representation을 배운다.
- 자연어 처리는 일반적으로 vocabulary size V가 클수록 좋으며, 실제로 V가 E보다 훨씬 큼
- 이로 인해 수십억개의 parameter가 있는 model이 쉽게 생성될 수 있으며, 대부분은 training에서 드물게 업데이트 된다.
→ ALBERT는 embedding parameter를 factorization하여 두 개의 작은 matrices로 분해한다.
V x X -> V x E + E x H- 이렇게 두개의 matrix를 연달아 곱하는 방식으로 token embedding을 만들기 때문에, factorized embedding임
- V는 크고 E,H는 작은 값이라서 parameter수 줄일 수 있음 -
- Cross-layer parameter sharing
- Transformer layer 간 같은 Parameter를 공유하며 사용
- network depth에 따라 parameter가 커지는 것을 방지해줌 → 모델 크기 작음
- parameter sharing이 network의 parameter 안정화에 영향을 주는것을 알 수 있음
- Inter-sentence coherence loss
- NSP를 개선하기 위해, SOP loss를 사용하여 문장간 일관성을 모델링함.
-
SOP loss는 동일한 document에서 두 개의 연속 segment를 positive sample로 사용, 두 개의 segment의 순서가 바뀐것은 negative sample로 사용한다.
→ 문장의 순서가 옳은지 여부를 예측
3.2. Model setup
-
훨씬 적은 parameter size

4. Experimental results
4.1. experimental setup
- Pre-train corpora: BookCorpus, Wikipedia (약 16GB)
- BERT와 동일한 input format: [CLS], [SEP], [SEP] 사용
- maximum input length:512 10% 확률로 512보다 짧은 input sequence를 random하게 생성.
- Wordpiece vocab size: 30,000 (BERT, XLNet)
- n-gram masking을 사용하며 각 n-gram masking의 길이를 random하게 선택
- n-gram 최대 길이: 3
- batch size: 4096
- optimizer: Lamb(You et al., 2019)
- learning rate: 0.00176
4.2. evaluation benchmark
- GLUE, SQuAD, RACE
4.3. overall comparison between BERT and ALBERT
-
ALBERT xxlarge > BERT

-
통신과 계산이 적기 때문에 ALBERT model은 BERT model에 비해 데이터 처리량이 더 높다.
- ALBERT-xlarge는 BERT-xlarge보다 2.4배 빠르게 train할 수 있다.
4.4. factorized embedding parameterization
- embedding size E=128이 제일 좋음
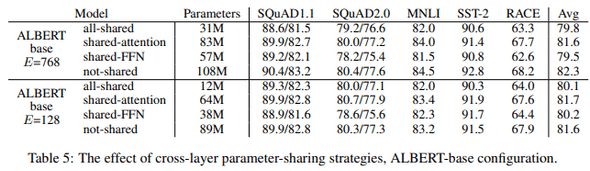
4.5. cross-layer parameter sharing
-
all-shared strategy는 두 조건 모두에서 성능을 저하시킨다.
-
attention만 share했을 때에는
not-shared와 차이 거의 없음 -
FNN을 share하면 성능차이 큼
4.6. sentence order prediction(SOP)
-
다음 세가지를 비교함
- none(XLNet and RoBERTa)
- NSP(BERT) → no benefit (topic shift만을 modeling함)
- SOP(ALBERT) → multi-sentence encoding task에서 개선됨
- NSP로 학습하면 NOP 성능 낮지만, 그 반대에서는 NSP의 성능도 좋음
4.7. what if we train for the same amount of time?
- 일반적으로 training time이 길수록 성능이 향상되므로 training step을 제어하는 대신 실제 training time을 제어하는 비교를 수행.
- BERT-large model(400k step)과 ALBERT-xxlarge model(125k step)의 training time은 거의 같다.(34h, 32h)
- ALBERT-xxlarge는 BERT-large와 거의 같은 시간을 training한 후 성능을 훨씬 더 좋음.
4.8. additional training data and dropout effects
- model capacity를 늘리기 위해 dropout을 제거(제거하면 MLM의 정확도 향상됨)
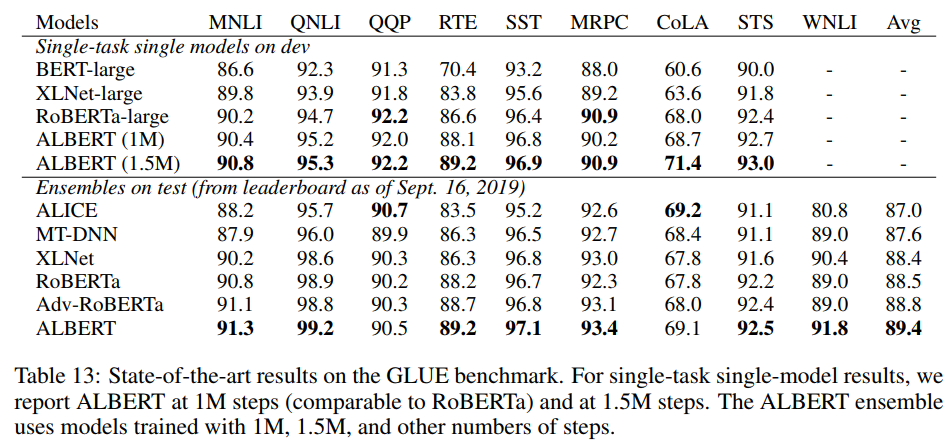
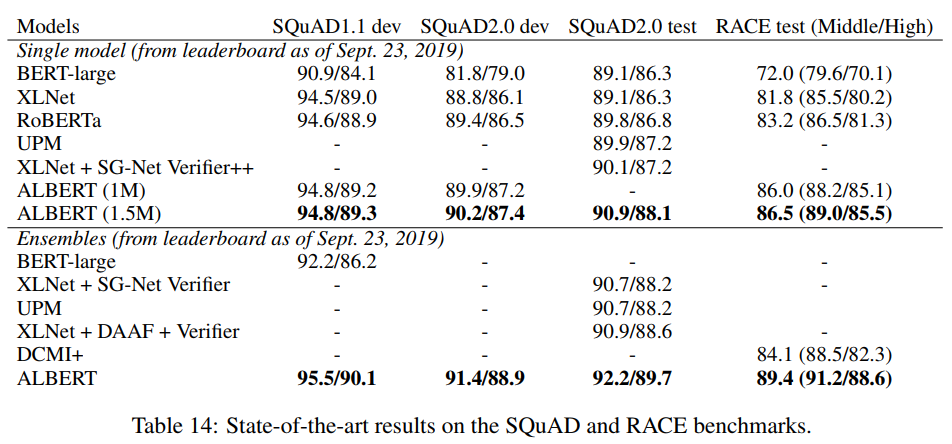
4.9. current state-of-the-art on NLU tasks
Appendix
-
network depth & width

-
do every wide albert needs to be deep too?

-
hyperparameters
-
downstream evaluation tasks
- GLUE, SQuAD, RACE,