[NLP/PLM] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Abstract
- large-scale pre-trained model로부터의 transfer learning이 대세임
- 본 논문에서는 small general-purpose language representation model인 DistilBERT를 제안
- building task-specific을 위한 knowledge distilation 진행
→ original BERT보다 크기 40% 줄임, 60% 빠름 → cheaper
1. Introduction
- large-scale pre-trained model로부터의 transfer learning이 대세임
- 특히 parameter 크기 즉 model size가 점점 커지고 있음
-
본 논문에서는 small general-purpose language representation model인 DistilBERT를 제안
→ original BERT보다 크기 40% 줄임, inference time이 60% 빠름 → cheaper
2. Knowledge distillation
- knowledge distilation
- compact model(student)이, large model(teacher)의 behaviour를 reproduce하도록 하는 기법
- training objective == model의 predicted distribution과 training label의 one-hot empirical distribution 사이의 cross-entropy를 minimize하는 것
- training loss
- teacher의 soft target probability에서의 distilation loss로 학습함
- softmax-temperature를 사용해서 학습함
3. DistilBERT: a distilled version of BERT
- BERT랑 동일, but 약간 다름
- token type embedding이랑 pooler layer 사라짐
- transformer block을 두배로 줄임
- initialization은 teacher의 레이어 두개당 하나를 취함
- gradient accumulation을 통해 large batch로 distilation적용함
- NSP 없이, dynamic masking 적용함
- BERT와 동일한 데이터로 학습
4. Experiments
4.1 Downstream task benchmark
-
GLUE, SQuAD, …
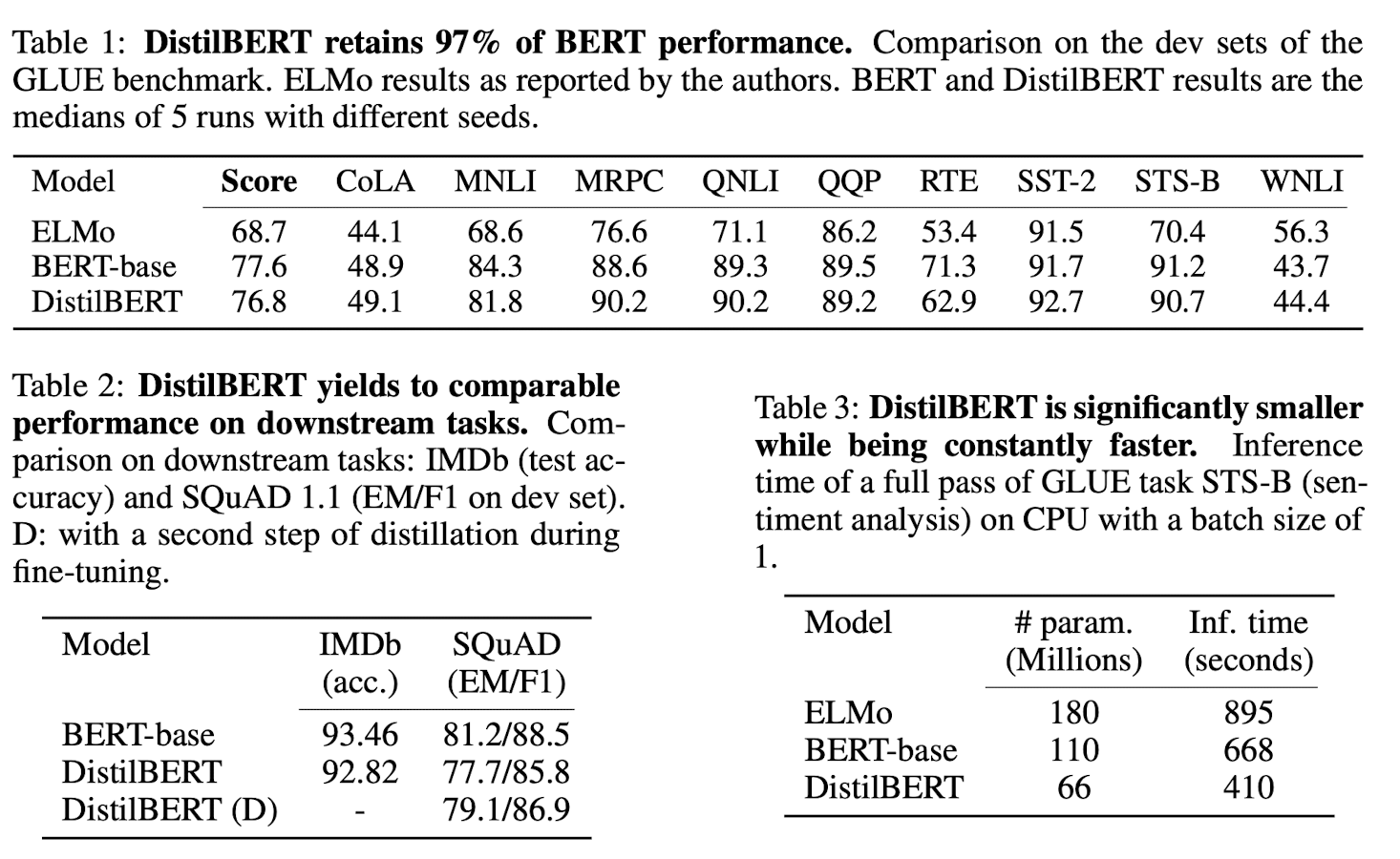
- size 40% 감소 & inference speed 60% 향상
- on device computation -
4.2 Ablation study
-
Masked LM loss를 없애는 것은 생각보다 성능에 큰 영향이 없었음
