*This paper was accepted to NAACL 2022 Main Conference *https://arxiv.org/abs/2204.05610
1. Background
- 최근 Knowledge-Grounded Dialogue Generation (KDG)연구는 rational하고 factual한 대화 위주를 생성해냄
-
Figure 1에서, 기존의 KDG는 human과 다르게 “pedantic” 즉 박식한 척 하는 대화를 생성하는 것을 알 수 있다. (사람의 대화에 비해 더 재수없음(?))

-
이렇게 knowledge만 강조하는 대화를 생성하면, KDG가 기계적으로 unstructerd knowledge(e.g. wikipedia)로부터 큰 섹션을 복사해 대답을 생성하게 됨
→ 이렇게 만들어진 대화는 less engaging & less natural …
-
2. Motivation
- 본 논문에서는, 위 단점들을 보완하기 위해 KDG와 stylized-text-generation을 통합하고자 함.
- bright style의 polite, positive response를 통해 response의 뜻을 농축시킬 수 있고, user가 더 매력을 느끼게 하며, 더 memorable해짐
- 본 논문에서는 새로운 problem을 정의함 : “model의 response는 dialogue context과 consistent가 있어야 하며, 주어진 지식 & 지정된 스타일 or 감정과 일치해야 함”
-
이 problem를 위한 ISSUE
1) dataset issue(<context, knowledge, stylized response>의 triple을 갖는 데이터가 없음)
2) context, sentiment도 중요하지만, correct knowledge여야 함
-
만약 knowledge에 style-related content가 포함된 경우, 기존의 stylized dialogue generation model은 지식의 correct를 훼손함

→ Figure 3에서의 “dislike cruel”과 “horrible”은 stylized fragment라서 positve로 수정되어야 하지만, “breaking bad”는 이름이라서 수정하면 안됨
-
-
- 위 ISSUE를 해결하기 위한 motivation
- disentangled template을 공유함으로서 separate knowledge-grounded response generation과 stylized rewriting을 연결함 → issue 1을 해결하기 위해
- reinforcement learning을 사용하여 주어진 지식에 대한 충실도 향상 → issue 2를 해결하기 위해
3. contribution
(1) 최초로 stylized knowledge-grounded responses generation 연구함 (style-specific context-knowledge-response를 위한 labeled paired data없이)
(2) disentangled template rewriting을 통한 stylized knowledge-grounded dialogue generation method를 제안함 + novel weakly supervised method를 곁들인 reinforcement learning
(3) 2가지 benchmarks를 통해 성능이 뛰어남을 밝힘 (SOTA 달성)
4. Disentangled Template Rewriting(DTR)
-
본 논문에서 제안하는 paradigm: Generate-Disentangle-Rewrite
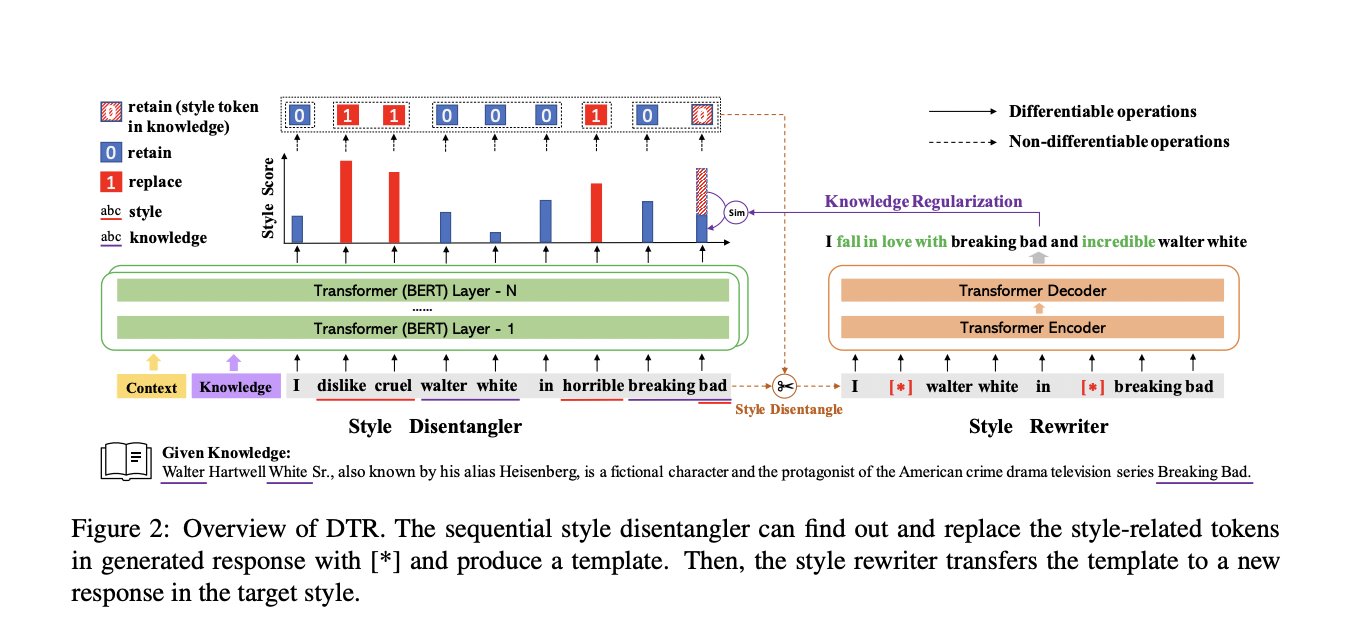
4.1. Task definition
- SKDG task를 위해, dialogue dataset $D_c =$ {$(K_i, U_i, Y_i)$}${i=1}^N$, style corpus $D_S=${$T_i$}${i=1}^M$에서 model 학습
- $U_i$ : dialogue context
- $K_i$: external knowledge
- $Y_i$: response to $U_i$
- $T_i$: target style S = {polite, postive, negative} 에서의 text piece
- $g_G$: knowledge-grounded response generator
- $F$: sequential style disentangler
-
$g_R$: style rewriter
- {(K,U,Y’)}의 triple은 없다고 가정
- Y’: style or sentiment S가 나타난 response
-
goal : $D_c$와 $D_s$로 generation method $P(Y K,U,S)$를 학습시킴으로서, 주어진 document K와 context U가 주어졌을때 desired style S에 맞으면서도 knowledge와 context를 유지하는 response Y를 생성하고자 함. - challenges
- supervision 없이 어떻게 주어진 sentence로부터 style-related fragment를 분리할 것인가?
- 완벽함을 위해 어떻게 knowledge section에서 style-related fragments를 유지할 것인가?
- 몇 가지 style word를 삽입하는 대신 disentangled template을 전체적으로 rewrite하여 fluency & diversity을 향상시키는 방법?
4.2. Process
- 주어진 dialogue context U와 관련 지식 K으로부터, $g_G$로 response $\bar{Y}$를 생성함 (
I dislike cruel walter white in horrible breaking bad) -
F가, 1에서 생성한 response중에서 style-related fragment를 제거함 (
dislike cruel,horrible)→ 이를 통해, style-agnostic template sequence $\tilde{Y}$을 생성 (
I [*] walter white in [*] breaking bad) - $g_R$이 token별로 전체 template를 재작성하고, 프로세스에서 style-related fragment을 주입하여 원하는 style로 vivid하고 informative한 응답 $\hat{Y}$을 생성함
(
I fall in love with breaking bad and incredible walter white)
4.2. Model Architecture
- Knowledge-Grounded Response Generator $g_G$
- Transformer architecture를 기반으로 하는 seq-2-seq architecture(6-layers encoder &decoder with a hidden size of 768)
- dialogue context U={$u_1, .., u_l$}와 관련 document K = {$k_1, …, k_h$}를 concat한 long sentence가 encoder의 input으로 들어가면, decoder가 response $\hat{Y}$를 생성
- Sequential Style Disentangler F
- 모델의 두 process(knowledge fragments generation & style fragments generation)을 decoupling하고 composition해줌
-
$\bar{Y}$에서 style-related word를 파악하기 위해, 각 position의 단어($w_i$)가 style-related word일 확률($x_i$)을 modeling함
- threshold ε: {$x_i$}$_{i=1}^m$의 $P_r$%의 Percentile이며, $P_r$은 hyperparameter
- $x_i$>ε이면 $w_i$가 style-related word
- 최종적으로 style-agnostic template $\tilde{Y}$를 생성함
- Style Rewriter $g_R$
- Transformer architecture를 기반으로 하는 seq-2-seq architecture(6-layers encoder &decoder with a hidden size of 768)
-
input으로 $\tilde{Y}$가 들어오면, $\hat{Y}$를 생성
- $\hat{w}_t$: length h를 가진 $\hat{Y}$의 t-th token
4.3 Reinforcement Learning
- style disentangler와 style rewriter에 대한 supervision이 없기 때문에, style intensity reward와 semanticsimilarity reward를 사용하여 end-to-end 방식으로 style disentangleling과 style rewriting을 훈련하는 reinforcement learning을 제안
- template-agnostic template sequence $\tilde{Y}$가 미분불가능하기 때문에, reinforcement learning approach와 $g_R$의 signal을 활용하여 F를 optimizing함
- reward를 주어 $g_R$과 F를 jointly learning함
4.4 Weakly Supervised Learning
-
두 모듈의 action space는 training에 취약하므로, disentangler와 rewriter를 모두 initialize하기 위해 novel weakly supervised stylistic template disentangle를 제안
→ paired training data없이, 원하는 스타일로 knowledgeable response을 성공적으로 생성 가능
- Weakly Supervised Disentangler
-
Figure 4에서와 같이, style fragment
good은 content fragementpizza보다 Ds에 대해 학습된 denoising auto encoder가 reconstructure하기 쉬움. 이는 style fragment가 content fragment보다 style corpus $D_s$에 영향을 많이 끼치기 때문임.
- $D_s$를 동일한 확률의 두개($D_s^1 , D_s^2$)로 나누고
-
$D_s^1$을 denoising reconstruction model $g_D$를 학습하는데 사용함
- $\tilde{T}$: T의 token 15%를 masking하여 corrupted한 version
-
$D_s^2$의 각 sentence $T =$ {$t_i$}${i=1}^m$를 한번에 하나씩 masking하여 denosing version인 {$\tilde{T}$}${i=1}^m$ 를 생성
→ $g_D$가 {$\tilde{T}$}${i=1}^m$ 를 {$\hat{T}$}${i=1}^m$으로 reconstruct함
→ 이후 disance sequence d= {$d_i$}${i=1}^m$ = {$Dis(t_i, \tilde{t}_i)$}${i=1}^m$을 얻어, 모든 가능한 $<t_i, t_j, y>$ triple로 $D_{st}$를 구성함
- $d_i<d_j$이면, y=1 (style-related token)
- $d_i>d_j$이면, y=-1 (content-related token)
-
-
Pairwise ranking loss를 통해 disentangler를 optimize함
- 이 loss를 통해 학습한 disentangler는, style corpus $D_s$={$T_i$}${i=1}^M$을 infer하고, disentangled template set $\tilde{D}_s$={$\tilde{T}_i$}${i=1}^M$를 생성함
-
- Weakly Supervised Rewriter
- rewriter는 $<\tilde{T}, T>$의 쌍을 각각 input, output으로 취함. 특히 $\tilde{T}$는 style-agm=nostic하기 때문에, rewriter는 factual sentence을 target style을 갖는 sentence로 변환하는 데에 중점을 둠
Experiments details
- 사용한 dataset
- KDG Corpus: Wizard of Wikipedia, Topical Chat datset
- Style Corpus: Amazon dataset, Politeness
- Evaluation Metrics
- Style Intensity를 측정하기 위해, GPT2 classifier prediction을 사용함
- Relevance를 측정하기 위해, F1, BLEU, Rouge
- 특히, baseline model은 knowledge selection module이 없으므로 ground-truth knowledge를 Wizard의 input으로 선택하고, Topical Chat의 input으로 BLEU-1에 의해 top-1 knowledge sentence를 선택하여 사용함
- Diversity를 측정하기 위해 Distinct 사용
- human evaluation에서는, 4가지 측면을 annotate : style consistency, knowledge preservation, context coherence, fluency
-
Baselines
dataset $D_c$와 $D_s$에 jointly하게 학습되며, knowledge와 context가 concate되어 input으로 들어감
- StyleFusion: https://github.com/golsun/StyleFusion
- StylisticDLV: https://github.com/golsun/StyleFusion
- StylizedDU: https://github.com/silverriver/Stylized_Dialog
- StyleDGPT: https://github.com/TobeyYang/StyleDGPT
Results
-
automatic evaluation 결과, DTR모델의 Style intensity가 대부분 제일 좋으며, wizard dataset이나 topical chat dataset의 모두(positive, negative, polite)에서 F1, Bleu 등 성능이 가장 좋았음.
-
human evaluation에서도, DTR이 제일 성능이 좋음
Ablation study
-
disentangler& weakly supervised learning method를 위한 3가지 variant
- w/o F WSL
- F의 Weakly Supervised Learnin없이 DTR을 training
- w/o F (Classification)
- F의 pairwise ranking loss를 binary classification loss로 대체함 (d = 0이면 style word, d=1이면 그 외)
- w/o F (TFIDF)
- F를 TFIDF-based rule로 대체 (stop word외의 단어를 제외하고, TFIDF score가 낮은 문장에서 fragment를 [*]로 대체)
- w/o F WSL
-
RL reward를 위한 3가지 variant
- w/o Rewards : similarity & style intensity reward를 제거
- w/o Sim: similarity reward를 제거
- w/o Cls: style intensity reward를 제거
Discussion
- Impact of stylized knowledge-grounded generation
- positive sentiment나 polite style을 도입하면 KDG 모델의 engaging가 높아지고, negative sentiment을 설정하면 매력도가 저하됨.
- Impact of style transfer on the conversational ability of SDG models (figure 5)
- style transfer 이후 대화능력이 얼마나 훼손되었는지를 확인하기 위해 두가지 setting에서 비교 실험
- Gold-K: 주어진 지식이 ground-truth임
- Predicted-K: 주어진 지식이 knowledge selection model이 선택한 것임
- style transfer 이후, DTR의 F1은 Gold-K와 Predicted-K에서 각각 2.28와 2.1 만큼 떨어짐 & StyleDGPT의 F1은 각각 11.16와 8.16 만큼 떨어짐
- Topical Chat에서 DTR의 F1은 GoldK와 Predicted-K에서 각각 1.77과 1.51, StyleDGPT의 F1은 각각 7.1과 6.16이 떨어짐
- style transfer 이후 대화능력이 얼마나 훼손되었는지를 확인하기 위해 두가지 setting에서 비교 실험
- Impact of the replace rate $P_r$ (figure 6)
- $P_r$=25에서 relevance와 diversity의 균형
- <25면, template에 많은 수의 original style fragment으로 남아 있어 서로 다른 스타일 간에 작은 차이가 발생
-
25면, rewriter로 복원하기 어려운 content fragment가 삭제되지만, 다른 스타일의 response가 다양해짐